
When I built my first web app, I had been programming for several years, but I knew nothing about web development. I turned to Rails (and an online course, Rails for Zombies) to find my way. What I’ll never forget is how valuable it was to have Rails’ guardrails. MVC became my mental model for web apps. has_one, has_many, belongs_to became my mantra for seeing the world of data modeling.
And as I got more comfortable, I started adding my own custom code to the mix — I wrote my own logic for guest/anonymous users, custom JavaScript, and stylesheets. I was never worried that I’d hit something that I couldn’t do with Rails.
I’ve hung up my Rails jacket (now I focus on Rust), but I continue to ask myself what I can learn from Rails when it comes to the problem I’m working on now: authorization.
Despite the fact that authorization is a problem as old as software, it’s core to just about no one’s domain. So most people are looking for a Rails-like experience. They want to be told how to think about authorization, they want drop-in patterns they can use, and they want to know they’re doing things in the right way. But they also want to know that in 6, 12, 18 month’s time, they’ll be able to achieve a longer tail of things that are specific to their use cases.
So, an authorization system needs to be opinionated but flexible – opinionated to get you from zero to best practices quickly, but flexible to support all the things your app needs. I’ll talk about why that is, why it’s a tricky balance to achieve, and what happens if you get it right.
Note: I'm Cofounder and CTO of Oso, a company that builds a system for application authorization.
The three components of authorization
First, just to get us all grounded, I’ll give a quick recap of the model for authorization that I laid out last year in Why Authorization is Hard – logic, data, and enforcement.This tiny snippet of Ruby contains all three:
Logic (AKA "modeling") is the generic rule set that governs who can do what in your application.For instance, the above snippet encodes the logic that only admins can update posts. It does so with an unless statement: unless user.admin?. The logic is simple in this example, but it tends to get hairy as more and more rules are introduced.Then there’s data. Logic encodes the rules themselves, and data (AKA "decision architecture") is the input to those rules. Data determines if the rules evaluate to true or not. In our example, the data is simply: who is an admin? The data might be stored as a column in the users table, or it might live in a third party authentication service. In more complex cases, data includes all kinds of other authorization-relevant data, like where a file sits in a filesystem hierarchy. The format of that data, along with where it is stored, is one of the three pillars of authorization.Finally, there’s enforcement. Inputting data into authorization logic and evaluating the result yields an authorization decision. Enforcement is the process of checking authorization decisions, and returning the results to your application code. If unless user.admin? is the logic, and the application supplies the data at runtime, then enforcement is everything else in that if block, most notably the raise Forbidden. Enforcement includes things like returning 403 errors to the client, or filtering the results in a search to those the user can see, and much more. It’s the integration layer between the application and its authorization.
Logic
Logic is core to every authorization system: it’s what defines who can do what based on your data. It’s what says that admins can delete organizations and that documents inherit permissions from their containing folders.All authorization systems need to provide a way to write this logic, either as code or as configuration. A method for authorization logic needs to be opinionated enough to get you going, but flexible enough to support the full breadth of modeling requirements that inevitably crop up.
Why it needs to be opinionated
An opinionated system for writing authorization logic gives you a plan. Most engineers don’t come to the table with strong opinions on how to model their domain’s authorization. The value of picking up a system off the shelf that tells you how to do it is you save yourself the time of making decisions, and hopefully the pain of making bad ones.For example, Casbin is a popular authorization library that imposes structure on the way you define roles. Here’s a Casbin CSV that grants user alice a role and then defines various permissions for that role:
Maybe you like it. Maybe it’s not the apple of your eye. But as a new Casbin user, you just bought your way out of thinking through a bunch of designs and considerations, and got straight to the end. You don’t need to work out your own way of configuring which roles can do what — it’s built into the system.
Why it needs to be flexible
But it’s not enough for a system to give you an opinionated way to build roles, because roles are the beginning for most apps, not the end. Any system for authorization logic needs to be flexible because of the sheer number of subtly different authorization models that most apps need. And if you’re thinking "we just need roles and attributes," read on and you’ll see what I mean.Take role-based access control (RBAC) — there are at least 4+ flavors, which you might want to support in various forms over time:
- Global roles: Roles that apply across the entire application. An example is internal superadmins vs customer support reps vs end-users.
- Organization-level roles: Like global roles, but segmented by organization or tenant. An example is admins vs. members at an organization in a B2B app.
- Resource-specific roles: Roles that apply at a more granular level in the application down to the (you guessed it) resource level. An example is Google Docs-style roles: editor vs. viewer vs. commenter. These are just roles, but users can have different roles on different docs! They can also inherit roles from parent folders, and so on.
- Custom roles: When enterprise customers want the ability to create their own roles from a set of available permissions, those are called custom roles. What makes these different is that something that was once static – role definitions – has now become dynamic.
Much like RBAC, there are a range of flavors of attribute-based access control (ABAC). These range from simple attribute checks to full-on dynamic systems like AWS IAM.
- Attribute checks: Most of the time when people talk about ABAC, they mean the ability to do simple attribute checks/comparisons on resources. Examples include: "anyone can read a resource if its public;" "users can’t do anything if they’re blocked;" "you can’t edit a resource if it was archived;" "user’s access expires on 2022-10-08;" and so on.
- Attribute add-ons: You can add attribute checks to other kinds of permission checks, too. It’s like an extra conditional tacked onto the original check. An example from GitHub is, "users can create private repositories if they are a member of the org, AND if the org allows private repository creation."
- Custom Policies: The most advanced form of ABAC is user-configurable policies. In this case, not only is the data dynamic, but so is the logic. And at this point, there effectively is no "model" – the model is whatever the user writes in their logic. An example of this is AWS IAM: the ultimate ABAC system.
Beyond simple RBAC and ABAC, there is a long tail of product requirements related to authorization logic. If you study this Github organization settings page, you’ll find at least 3 authorization logic challenges that don’t cleanly fit into "RBAC" or "ABAC":
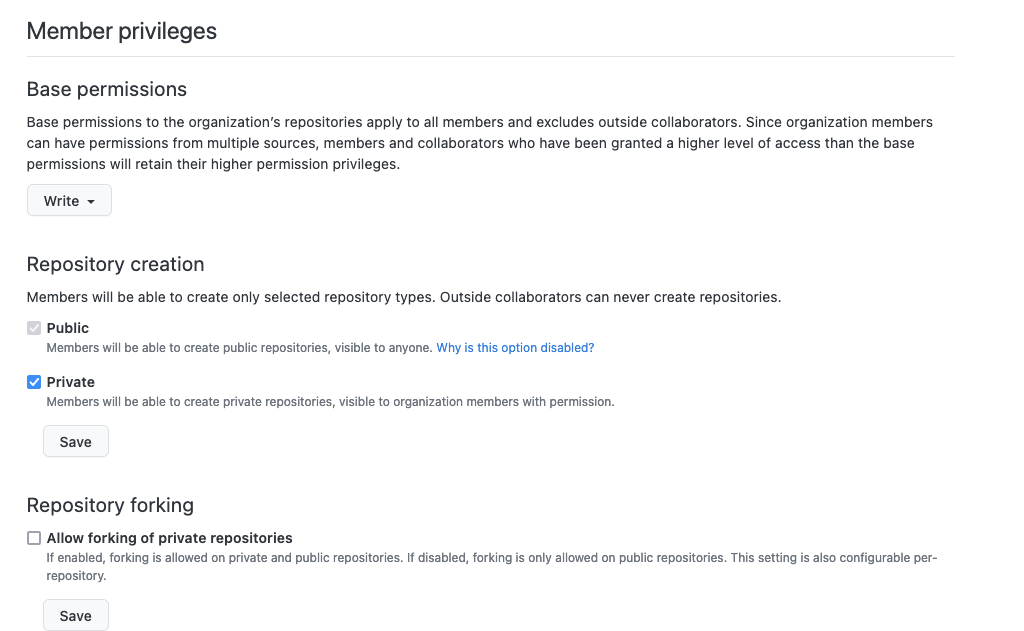
There are a ton of authorization models: more than I could possibly list here. At Oso we’ve compiled 10 of the most common patterns and provided an opinionated way to build them, but there’s another 12 we haven’t got around to, and certainly more to come.An app may not need to support all of these patterns on day 1, but quickly evolves to need new models and typically many of them together. If your authorization system prevents you from expressing the logic for, say, custom roles, and then your customer turns around and asks for custom roles, you now have two options: either you refactor to a different authorization system, or hold your nose and ship a lot of hacks to release the feature.The best authorization systems need to support the full spectrum of authorization models without a refactor, and without introducing cruft to the rest of your app. As an example, when using Oso Cloud, you write policies in Polar, a declarative policy language built for authorization. Polar has opinions on how to define things like roles and permissions, but you can also write logic for long-tail rules like "organization members can create private repositories if the organization allows that":
There are other ways to maintain flexibility in authorization logic — it’s actually why many teams opt to hand-code their authorization systems themselves. But while hand-rolling your own logic gets you flexibility down the line, it sacrifices on being opinionated — you have to determine your own best practices upfront and build your own standards to make common patterns easy to express.An opinionated but flexible system for authorization logic lets you get started with the basics quickly, while also letting you grow into complex requirements over time.
Data
All authorization decisions use data: to decide who can do what, you need access to user roles, resource relationships, attributes, and more. An authorization system needs to perform arbitrary queries over that data, so the data needs to be expressed in a format that makes those queries fast.This is a particularly pressing concern when your architecture grows to include multiple services — you need a common data format for all authorization-relevant data, and you need a place to centralize any shared data (like roles) that you can query efficiently for permission checks.The format needs to be opinionated enough to provide that standard format and to make the system fast, but flexible enough to implement all of the use cases your app will encounter.
Why it needs to be opinionated
For example, take Google Zanzibar, Google’s centralized authorization system. Zanzibar is highly opinionated in its data format. It has you model all data – i.e., any part of your domain that touches authorization – as relation tuples. Relation tuples takes the form:
- has a relation with
- Alice is a member of group foo: *group:foo#member@user:alice*
- has a relation with all s who have a relation with
- All members of foo are admins of document 123: *document:123#admin@team:foo#member*
Google’s implementation is proof of the ability for this data model to scale. What makes it so fast is that practically all authorization queries are just a series of joins between objects of the form type:id.
Even this constrained tuple format, Google still needed to do hot-spot mitigation, plan in advance of large events, and spend time on per-team schema optimizations to make Zanzibar fast enough!
Why it needs to be flexible
The trick is ensuring that you haven’t mortgaged your use case coverage with the performance you just bought.
Zanzibar is a great fit for domains that you can model easily as relationships (e.g. Google Drive), but struggles with attribute-based used cases.
It can stretch to simple use cases, like toggling a repo as public or private. To do this, though, you need to rethink public/private in terms of relationships. With relation tuples, public repos are repos where "all users have the read relation with this repo." There are a long list of other use cases, though, which Zanzibar doesn’t support, like default roles and attribute add-ons, described earlier.
How can we provide a useful data structure for authorization data while maintaining flexibility? In Oso Cloud we represent data using a name and a variable number of arguments, called a fact. Facts are similar to Datalog implementations like Datomic, or RDF triples. The structure of a fact is a name, and a list of arguments. For example, roles, relationships, and attributes can all be written with facts:
The upshot is you get a specific way to structure your data, that fits tightly with common cases plus the long tail of cases too.
Under the hood, querying facts is fast. Evaluating a policy spits out a bunch of facts that Oso Cloud needs to look up. Much like in Zanzibar, this is basically a few SQL joins over a heavily indexed relational database.
You can also go further towards flexibility when it comes to authorization data. Open Policy Agent (OPA) uses JSON as the format for all authorization data. There’s no doubt that JSON is flexible — you can serialize any data into JSON. But it does sacrifice some of the opinionated-ness that Zanzibar and Oso use to drive performance. For some cases this may not be an issue. But in many cases, you need to optimize queries by hand, as the engine doesn’t have an a priori understanding of the underlying data model (and how to index it so it’s fast).
Having a data format that is both opinionated AND flexible lets an authorization system optimize queries itself, while also letting the developer express whatever data they may need for their use case.
Enforcement
Now that you’ve figured out how to write the logic, and where to put/manage the data, what’s left is figuring out how to actually go and add the damn thing to your application. This is enforcement.
Enforcement needs to be opinionated, at a minimum, so you have a single approach and a clean boundary between your authorization system and application. But it needs to be flexible enough to integrate anywhere in your stack and to ask all the questions you’ll need to ask.
Why it needs to be opinionated
You want a single approach to enforcement because it is the boundary between your authorization logic and your application logic. Keeping it consistent is what lets you change your authorization logic without having to go change all your enforcement checks. It also gives you a target for logging and debugging, as all decisions are going through one pipe.We opened this post talking about Rails — Rails authorization libraries provide great examples of opinionated enforcement. Rails is the king of don’t repeat yourself (DRY), and you see that in the ecosystem built up around it.For example, the authorization library Pundit has a number of useful abstractions for authorization, which work well because of the conventions that you get from Rails:
In this example, the authorize method is built into the framework, and it infers the current user, as well as the verb from the method name. With this in place, I can go and change my Pundit policy to my heart’s content – without having to come back and touch the update method (and all the other places I’ve conceivably put it in my code).
Pundit has two main conventions:
- The builtin *authorize* method to authorize "can a user perform action on this resource?"
- Scopes for filtering data based on authorization using ActiveRecord query filters.
Together, these two opinionated methods can get you pretty far, and they buy you the goals described earlier – single approach, clear boundary, and target for logging and debugging.
Why it needs to be flexible
But you need to do enforcement all throughout your app, and in many different forms. You need to enforce up and down the stack, from the frontend, to the controllers, to the database. Sometimes you need to authorize in bulk, sometimes you need to get all the permissions a user has to return to the UI, sometimes you need to find all the people who have access to a thing.Although Pundit can handle some enforcement use cases (in fairness, the two most common ones), it’s also common that apps need to ask other types of authorization questions:
- "What are all the permissions this user has on this resource?" (Handy in the UI)
- "Who are all the users that can see this resource?"
- Combinations of any of these: "What are all the permissions this user has on all resources of type ?"
- … and any other custom question that isn’t listed here that you might need, like "What are all the users that belong to the organization that the user can assign a role to?"
As soon as the authorization system can’t handle a case you need, you need a new strategy for that case – and as part of that, you’ll have to reimplement all your authorization logic too.Some authorization solutions, like Oso and Open Policy Agent (OPA), are based on logic programming languages, like Datalog and Prolog.Logic languages (which are in the declarative family) are built around the concept of "querying" rather than executing code. So for example, in Prolog you might have a predicate to compute the length of a list length(List, Length) , which you can query in all kinds of waysFrom the expected:
- length([1, 2, 3], 3) returns true
- length([1, 2, 3], L) returns L=3
To the more bizarre:
- length(List, 3) returns List=[X1, X2, X3] (a list with three variable members)
- length(List, Len) returns List=[], Len=0 , List[X1], Len=1, …
The same principle applies to what you can do in Oso. For example, you write authorization queries in Oso as allow (actor, action, resource), where actor, action, resource are variables. You can ask for any combination of variable or fixed arguments. For instance, to ask, "What are all the actions John can perform on the Anvil repository?" you would write allow(User:job, action, Repository:anvil).
For the most common cases, Oso wraps the query interface with APIs for yes/no authorization questions, returning a list of authorized resources, and a handful of others.
An opinionated but flexible system for enforcement gives you a clean separation between authorization code and application code, while also allowing you to perform authorization in every way your app may need.
What’s next
I come back to my original claim that an authorization system should be opinionated but flexible – opinionated to get you from zero to best practices quickly, and flexible to support all the things your app needs.
- Logic should give you a path for the simplest access control models, and the flexibility to support the full range of models.
- Your data format should give you a consistent way to share data across services (and in a way that’s performant), while ensuring you can easily implement the same models in your logic.
- As for enforcement, it wants for a single API so you can change your logic independently, but it also needs to let you ask the full range of the questions you need in all the places you need.
And still, there’s a lot I didn’t have time to cover in this post – what data to store where in an N>1 services backend, or how to instrument your authorization for logging and debugging, to name a couple. I’m planning to do more scribbling in the coming months. In the meantime, feel free to reach out to me with any feedback at sam@ this domain.
Finally, if you’re interested in these problems and their solutions, I invite you to take a look at Oso Cloud. We’ve spent years thinking about this tradeoff of opinionated vs flexible. As you might be able to tell, I’m proud of where we’ve ended up. There’s still more work to do.
P.S. Shout out to Graham Kaemmer (GK) for all his help thatwent into this post.
Frequently asked questions
