OpenFGA is an open-source authorization framework.
Both it and its commercial counterpart, Okta FGA, are interpretations of the Zanzibar whitepaper, which describes the Relationship-Based Access Control (ReBAC) authorization model used at Google. OpenFGA allows developers to define complex application authorization policies using a declarative language.
Why consider alternatives to OpenFGA?
While OpenFGA offers powerful capabilities for access control, you may want to consider alternatives based on specific needs such as ease of implementation and cost of maintenance.
OpenFGA requires that you to replicate data to a secondary data store, which may create more operational overhead than you want to take on. Its rigid ReBAC implementation may not map naturally to your authorization logic. These considerations determine how well a given solution meets your specific organizational constraints and development requirements.
Top 4 alternatives to OpenFGA
The following section will compare and contrast Oso Cloud, Permit.io, Permify and AuthZed.
1. Oso Cloud
Oso Cloud provides application authorization as a service. It diverges from OpenFGA and other Zanzibar-based ReBAC implementations in two fundamental ways.
a. Data architecture: Oso Cloud is able to answer authorization questions using data directly from your application databases. You can gain all the benefits of centralizing your authorization logic - discoverability, sharing, testing - without having to build extra logic to synchronize you application data to Oso Cloud. When you’re getting started with Oso Cloud, you can focus entirely on your authorization logic. You don’t have to worry about how to get your data to it. But don’t worry - if you decide later that you want to centralize some or all of your authorization data, Oso Cloud supports that, too. Whether you use OpenFGA or Okta FGA, you have to copy your authorization data out of your application databases to a separate store that the service uses specifically to answer authorization questions. This introduces all the extra overhead that comes with maintaining two sources of truth: initial data replication, two-phase commits, and drift detection and remediation. You’ll need to manage this from the start.
b. List filtering and LLM permissions. Oso enables you to easily answer questions like “What are all the documents this user can view?” Oso generates filters from your authorization policy so your database returns only authorized results. This is especially important for AI use cases where you need to ensure AI pipelines (search, RAG) return only the data a user is authorized to access.
OpenFGA was designed for static, relationship-only permissions, not dynamic AI pipelines. List filtering queries are inefficient and can take seconds, making them unusable for AI responses.
c. Semantic flexibility: Authorization logic in Oso Cloud is written in the Polar language. Polar is a general purpose logic language that allows you to ask authorization questions in direct terms. Fundamentally, authorization is the act of answering the question “Can User A perform action B on Entity C?” In a ReBAC model like OpenFGA, you can’t ask this question. Instead, you have to ask “Does User A have relation R with Object O?”
d. Expressive logic: Likewise, OpenFGA and similar systems are only capable of expressing authorization logic in terms of relationships. While it’s possible to do this, in reality much authorization logic isn’t relational. This makes it difficult to support common use cases like global permissions and public objects in OpenFGA. Rather than simply granting an administrator edit access to all organizations or marking a document as public, you have to work around the constraints of the language to figure out how to make those rules look like relationships. In Polar, you can directly express these ideas.
2. Open Policy Agent
Open Policy Agent (OPA) is an open-source policy engine for policy enforcement across your stack. Teams use OPA to enforce policy-as-code across microservices, kubernetes, and other infrastructure components.
Deployment model: OPA can be deployed as a sidecar, host-level daemon, or library.
Modeling: OPA uses a high-level declarative language called Rego for policy definition. While powerful, the Rego language has a significant learning curve. As a general-purpose tool, it also lacks application-specific authorization primitives.
Data: OPA accepts data from a variety of systems in their native format, and Rego allows you to transform data to enforce authorization decisions.
While OPA is available as open source software, its maintainers were recently hired by Apple, and there is no longer a commercial company or offering behind it.
3. Permify
Permify is an open-source, Zanzibar-based solution similar to OpenFGA. It is the most pure open-source implementation in this evaluation.
a. Deployment Model: Permify is a self-hosted solution that you deploy on your infrastructure. They provide a docker container or you can build it from the source code.
b. Data Management: Permify stores authorization data in a dedicated store that you set up within your infrastructure.
c. Modeling: Both OpenFGA and Permify are ReBAC solutions inspired by Google Zanzibar. Permify provides an attribute extension that supports attribute-based access control (ABAC) scenarios like public documents more naturally.
4. AuthZed / SpiceDB
Authzed is another Zanzibar-based authorization as a service solution. It provides managed and self-hosted implementations based on the open-source SpiceDB project.
a. Deployment Model: AuthZed provides both cloud and on-premises deployments. It is distributed as a docker container, in the package managers of most common Linux distributions, or as a chocolatey package on Windows.
b. Data Management: AuthZed stores authorization data in a dedicated store that you deploy and manage within your infrastructure. It offers the widest database support of all the solutions evaluated here.
c. Modeling: Both OpenFGA and Authzed define pure Zanzibar-based ReBAC authorization models.
Feature comparison table
Feature
Oso Cloud
OpenFGA
Local Deployment Model
On-premises binary installation
Open-source, self-hosted
Modeling
Support for arbitrary authorization logic using Polar
Authorization logic must be modeled in terms of relationships
Data Architecture
Keep data in your existing database or centralize in Oso Cloud
Data must be copied to a separate store and kept in sync
Why choose Oso Cloud over OpenFGA?
Oso Cloud and OpenFGA are both powerful application authorization solutions. Oso Cloud provides the Polar language, which allows you to express all of your authorization logic in the most natural terms. OpenFGA is based on Google Zanzibar, and as a result requires you to express all of your authorization logic in terms of a relationship between two objects. Oso Cloud can use your application data in-place, so you don’t have to synchronize anything to an external store to start answering authorization questions.
OpenFGA and Okta FGA both require you to copy authorization data to an external data store, which creates extra operational overhead for your team. Oso Cloud provides that more streamlined onboarding experience of the two. Because it always allows you to express your authorization logic in the terms that best fit your mental model, it is also the easier solution to maintain over time.
Conclusion
OpenFGA is a powerful solution for application authorization. But you may find that other options better meet your needs. If you’re already using a policy engine like OPA or AWS Cedar, or if you want to make it easier for business users to manage authorization logic, then Permit.io is a great choice. If open-source is a priority, then take a look at Permify. If you want support for a wide variety of databases, then look at authzed.
For all their strengths, all of the above solutions introduce friction into the developer experience. Whether they force you into an unnatural mental model, require a data replication mechanism, or simply lack dedicated, reliable support, you may find that while they meet your authorization requirements, they fall short of your organizational needs.
Oso Cloud has been built from the start to provide an exceptional developer experience. It allows you to model your logic in the terms you already use to think about it. It lets you keep your data in one place, simplifying your code and your infrastructure. This creates a simple path to adoption while supporting the most sophisticated application requirements. Oso provides comprehensive testing and diagnostic features as well as an unmatched support experience to make sure you get to production with confidence.
Ready to give Oso Cloud a try? Head over to our Quickstart to get up and running in a few minutes! Still have questions? Reach out to us on Slack. We’d love to talk authorization with you.
Fine-grained authorization (FGA) controls who can do what, on which resource, and under what conditions based on roles, relationships, and context.
Traditional models like RBAC (role-based access control) are too rigid for modern, dynamic systems, often leading to over-permissioning or patchy enforcement.
FGA enables precise, contextual decisions like allowing access only during business hours, within certain departments, or on specific resource fields.
With tools like Oso, you can define policies once and enforce them consistently across APIs, services, UIs, and even AI agents.
Imagine this: a customer support agent logs into your admin dashboard and uses the impersonation tool to investigate an issue. Nothing wrong with that until they accidentally access and edit sensitive billing data. No malicious intent. But the impact? Real. Unintended data changes, compliance violations, and hours of rollback effort.
The problem wasn’t just human error. It was the authorization logic that was too coarse. Anyone with the "Support" role could impersonate any user, access any feature, at any time.
These kinds of failures are more common than you think. And as modern systems get more complex, with layers of automation, multi-tenant environments, and integrations with AI agents, the need for real-time, contextual access control is no longer optional. It’s critical.
That’s where fine-grained authorization comes in.
FGA lets you move beyond one-size-fits-all roles and build access rules based on context, relationships, and intent. Instead of saying, "Support agents can impersonate users," you can say:
"Support agents can impersonate users in their region, during business hours, and only on non-sensitive resources."
FGA is about precision. About ensuring that permissions reflect the real-world boundaries your business needs.
Coarse vs. Fine-Grained Authorization
Here’s a quick comparison between Coarse and Fine-Grained Authorization:
Feature
Coarse-Grained (RBAC)
Fine-Grained (FGA)
Permissions assigned by
Roles
Rules, context, relationships
Resource scope
Application-level
Field-, record-, or attribute-level
Flexibility
Low
High
Auditability
Moderate
Strong
Enforcement
Hardcoded
Declarative and centralized
The Limitations of Coarse-Grained Access Control
Coarse-grained models like RBAC and even ReBAC (Relationship-Based Access Control) were designed for simpler systems where everyone can access each and every resource or with more than required permissions. They assume permissions can be defined by either what role a user has or how they relate to a resource. And in some cases, they work well enough.
But as your system grows, so does its complexity. Here are the cracks that start to show:
Rigid roles: Want to give a user edit access to just one project, but read access to the rest? Tough. You’ll need a new role or worse, custom logic.
Over-permissioning: With broad roles like "Admin" or "Manager," users often get more access than they actually need.
Inconsistent enforcement: One service checks for roles, another checks relationships, and a third bypasses checks entirely for performance. There’s no uniform standard.
Hard-to-audit systems: With rules spread across controllers, YAML, and SQL, answering "Who can do what?" becomes guesswork.
This sprawl not only makes debugging a nightmare, but it also creates real security risks. Without clear, context-aware rules, your system becomes a patchwork of special cases and exceptions.
Why Coarse-Grained Access Control Doesn’t Scale
Modern systems don’t live in a monolith anymore. They’re made up of dozens, sometimes hundreds of services, each with its own responsibilities, data models, and deployment lifecycles. And these services interact with external partners, embedded AI agents, federated identity providers, and region-specific infrastructure.
Here’s where things start falling apart:
Dynamic organizations: A user’s permissions can’t be defined by a static role if they inherit access via departments, projects, or org charts that change weekly.
Shared data: Multi-tenant architectures make it dangerous to apply the same role globally, and permissions must be scoped per tenant, project, or environment.
API layers: Data moves through internal APIs, public APIs, and third-party integrations. If your access control isn’t enforced consistently, you’re relying on trust.
Microservices: Each service might enforce authorization differently or not at all. Without a shared policy, your enforcement logic becomes fragmented.
What Is Fine Grained Authorization (FGA)?
Fine grained authorization (FGA) is an access control approach where permissions are determined not just by a user’s role, but by a combination of attributes, relationships, and contextual data. It answers more than just “who are you?”. It asks:
What are you trying to access?
What are you trying to do?
Under what conditions should that be allowed?
Unlike traditional models that rely on fixed roles (RBAC) or just resource ownership (ReBAC), FGA considers multiple data points to make smarter, safer, and more dynamic decisions.
How FGA Works in Practice
Let’s break it down into components:
Roles: What position or function does the subject hold?
Relationships: How is the subject linked to the resource (e.g., owner, teammate)?
Context: What’s happening right now - time, location, device, or action type?
Attributes: Metadata about users or resources, like department, sensitivity level, or subscription tier.
Put together, these factors enable highly specific and enforceable rules. For example:
"Allow a user to view medical records only if they are the patient’s assigned doctor, and they’re accessing from a hospital IP address, during business hours."
That’s FGA in action - layered, dynamic, and secure.
Real-World Examples of Fine-Grained Access Control
Here’s where FGA stands out over coarse-grained models:
Scenario
Why FGA Is Needed
Traditional Approach Falls Short Because…
File system access
Permissions vary by file, folder, and user context (e.g., read-only access to archived files)
RBAC can’t handle folder-level exceptions or temporary access rules
Conditional impersonation
Support agents can impersonate users, but only within their region and non-sensitive contexts
ReBAC can say “you can impersonate,” but not when or how
Tiered entitlements
SaaS users with “Pro” plans can export data and get API access, while “Free” users can only view
Roles alone can’t reflect product entitlements or usage limits
Field-level visibility
HR can see employee names and job titles, but only Finance can view salary
RBAC doesn’t support visibility restrictions at the field or attribute level
AI/LLM access boundaries
AI agents should only access content the invoking user is permitted to see
Context isn’t preserved in role-based systems leading to potential data leaks
FGA isn’t just about security, it’s about precision. It lets you confidently say yes when it’s safe, and no when it’s not, without guessing or over-restricting. And as your product, team, or automation layer scales, that nuance becomes non-negotiable. So let’s look at how FGA works.
How Fine-Grained Authorization Works
At its core, fine-grained authorization (FGA) is about evaluating access based on multiple dimensions and not just “who” someone is, but what they’re doing, what they’re trying to access, and under what conditions.
The Key Elements of a Fine-Grained Policy
Fine-grained authorization operates on four fundamental inputs:
Subjects: These are the entities performing an action, which are commonly users, service accounts, AI agents, or even automation scripts. For example: a support agent, a CI/CD bot, an AI assistant answering customer queries
Resources: The application being accessed. This could be a document, a product, a database row, a UI component, or even a field within a record. For example: a specific user account, a product listing in a multi-tenant database, a salary field in an employee record, etc.
Actions: What the subject is attempting to do in the application. For example: view, edit, delete, transfer, or impersonate
Conditions: Additional context is used to approve or deny access. These are dynamic factors that change depending on the situation. For example: time of day (e.g., business hours only), geo-location (e.g., office IP address), device type (e.g., company-issued laptop), or organizational membership (e.g., only team leads in “Region A”)
Together, these inputs are evaluated by a policy engine like Oso that returns a decision: allow or deny.
Conditions = Dynamic filters like geo-location, time, and org scope
This table shows how access decisions vary not just by subject and resource, but also based on the action attempted and the conditions applied in context.
Models that Enable FGA
Several access control models enable or contribute to fine grained permissions. Here’s how they break down:
1. ABAC – Attribute-Based Access Control
Access is granted based on attributes (tags, labels) of users and resources.
Example: Allow a user with department=Finance to access invoices with region=APAC.
Weaknesses: Can become complex to manage and debug if uncontrolled.
2. ReBAC – Relationship-Based Access Control
Access is based on the relationships between subjects and resources.
Example: Allow users to comment on a project only if they are listed as collaborators.
Strengths: Great for multi-tenant systems and collaborative platforms.
Weaknesses: Doesn’t account for dynamic context (e.g., time, location).
3. Hybrid Authorization (e.g., Oso’s Model)
Combines RBAC, ReBAC, ABAC, AnyBAC into a unified, declarative policy system.
You define roles, model relationships, and layer on attributes and conditions.
Example: “Allow a Collaborator to edit a document if they are assigned, and the document is not archived, and it’s accessed during business hours.”
RBAC vs ABAC vs ReBAC vs FGA
Here’s a quick RBAC vs ABAC vs ReBAC vs FGA comparison to understand how each model stacks up
Feature
RBAC
ABAC
ReBAC
FGA (Hybrid)
Based on roles
✅
❌
❌
✅
Based on attributes
❌
✅
❌
✅
Based on relationships
❌
❌
✅
✅
Contextual conditions
❌
✅
❌
✅
Ideal for microservices
⚠️ Limited
⚠️ Can be hard to maintain
✅
✅
Best for dynamic decisions
❌
✅
⚠️ Not always enough
✅
Example use case
“Admins can edit all”
“Editors in US region only”
“Users in team can comment”
“Assigned editors, in US, during work hours”
What Makes Fine Grained Permissions Hard (and How to Get It Right)
Fine-grained authorization promises powerful, precise access control but it also comes with real challenges. When done wrong, it leads to brittle systems, unscalable policies, and developer frustration. To understand why, let’s break it down.
The Complexity Problem
Fine-grained means more conditions, more rules, more precision. But all of that comes at a cost:
More rules lead to more edge cases: It’s no longer enough to check if someone is an "Admin". You might need to evaluate whether they're accessing a resource in a specific region, during a specific time window, under a certain project tag. That’s a lot more surface area for bugs.
Conditional logic vs. deterministic logic: Role checks are usually binary. You’re either an admin or you’re not. But with FGA, permissions can depend on runtime context. For instance, "A user can view this report if they’re in the same department, and it’s not older than 30 days." These conditions can’t always be cached or assumed, making testing and reasoning harder.
Transient permissions: Time-based or event-driven permissions (e.g. "access valid for 24 hours" or "access granted during incident response") require systems that understand expiry, state, and revocation. Traditional models don’t handle this well, and rolling your own logic is error-prone.
Multiple layers of enforcement: You can’t just enforce permissions at the UI. You need to enforce them at the API layer, database layer, and even in internal automation, each of which might have different enforcement patterns or caching logic.
FGA is powerful, but with power comes complexity. Unless you manage it well, you’ll end up with policies nobody understands and behavior nobody can predict.
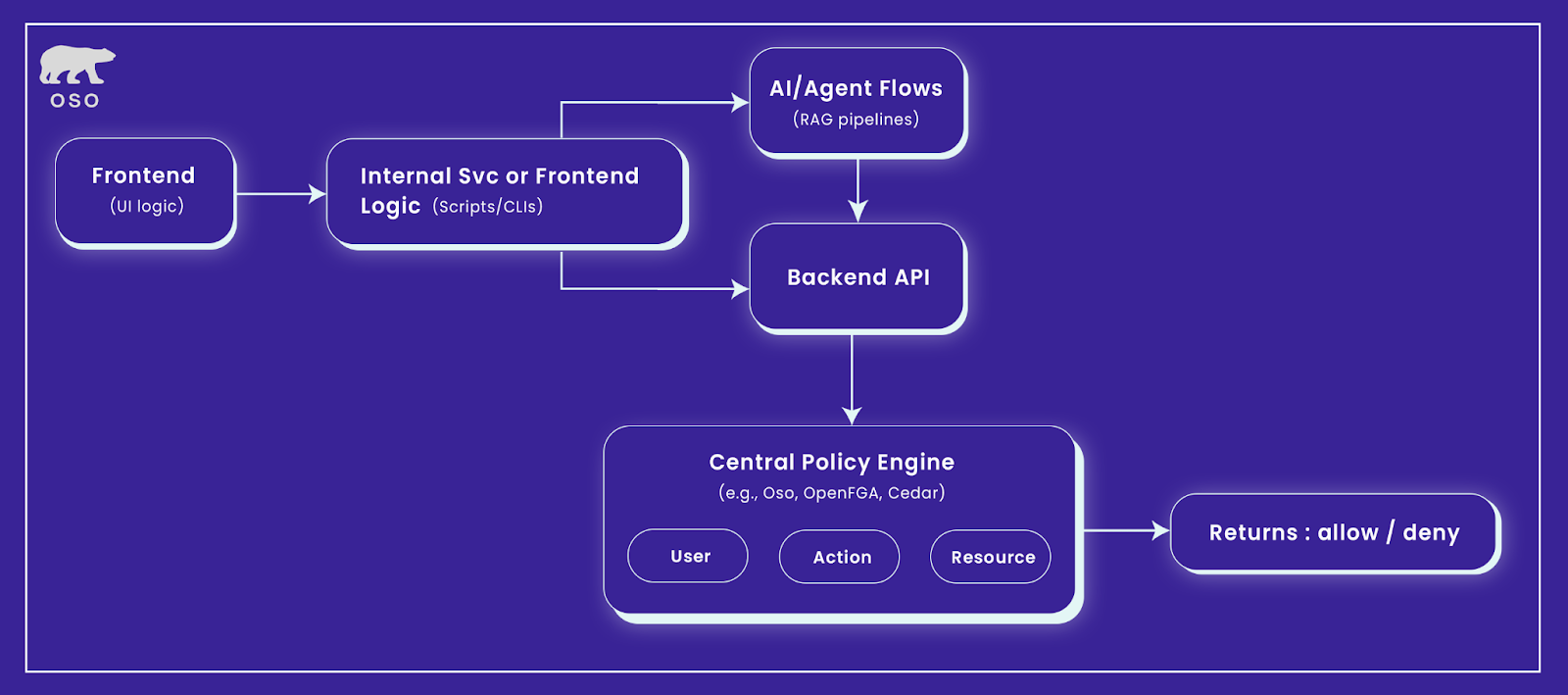
The Solution: Central Policy + API Enforcement
The good news? These challenges can be solved with the right architecture.
The key is to decouple policy logic from enforcement logic. That means:
Define your access rules once, using a declarative language in a central policy engine.
Keep your policies versionedand testable, just as you would treat code.
Push enforcement to the edges, but always reference the central policy when making decisions.
This separation allows teams to:
Maintain a single source of truth for all access decisions
Re-use policy logic across services, UI, and tools
Easily update or audit access rules without touching application code
You define the “who, what, when” in a centralized authorization engine. APIs, microservices, UIs, and agents query that logic via API or SDK calls (e.g., isAllowed(user, action, resource)). The authorization engine returns deterministic results based on real context.
All components query the central engine for authorization decisions. This decoupled architecture turns fine-grained authorization from a tangled mess of “if” statements into a maintainable, scalable part of your infrastructure where changes are safe, reviewable, and fast to propagate.
With tools like Oso, you can express complex policies across roles, relationships, attributes, and conditions and enforce them across your stack without rewriting business logic.
Next, let’s look at how Oso makes this practical.
How Oso Makes Fine-Grained Authorization Practical
Fine-grained authorization sounds powerful in theory, but in practice, it’s only useful if your team can implement and maintain it without tearing your app apart. That’s where Oso comes in. It lets you express RBAC, ReBAC, and ABAC all in one consistent, readable language, so you don’t have to pick just one model or rewrite your logic when your access needs evolve.
With Oso, policies are defined in a declarative .polar file that acts as a centralized source of truth for permissions. These policies are:
Reusable: Define access rules once, use them across APIs, services, and UI
Testable: Unit test your policies like any other logic, with clear input/output behavior
Auditable: Review changes to access logic in Git just like you would with code
This means your access model is no longer buried in controller files, YAML, or ad-hoc middleware. It’s structured, versioned, and consistent, ready to scale as your team or product grows.
Oso Cloud Lifecycle
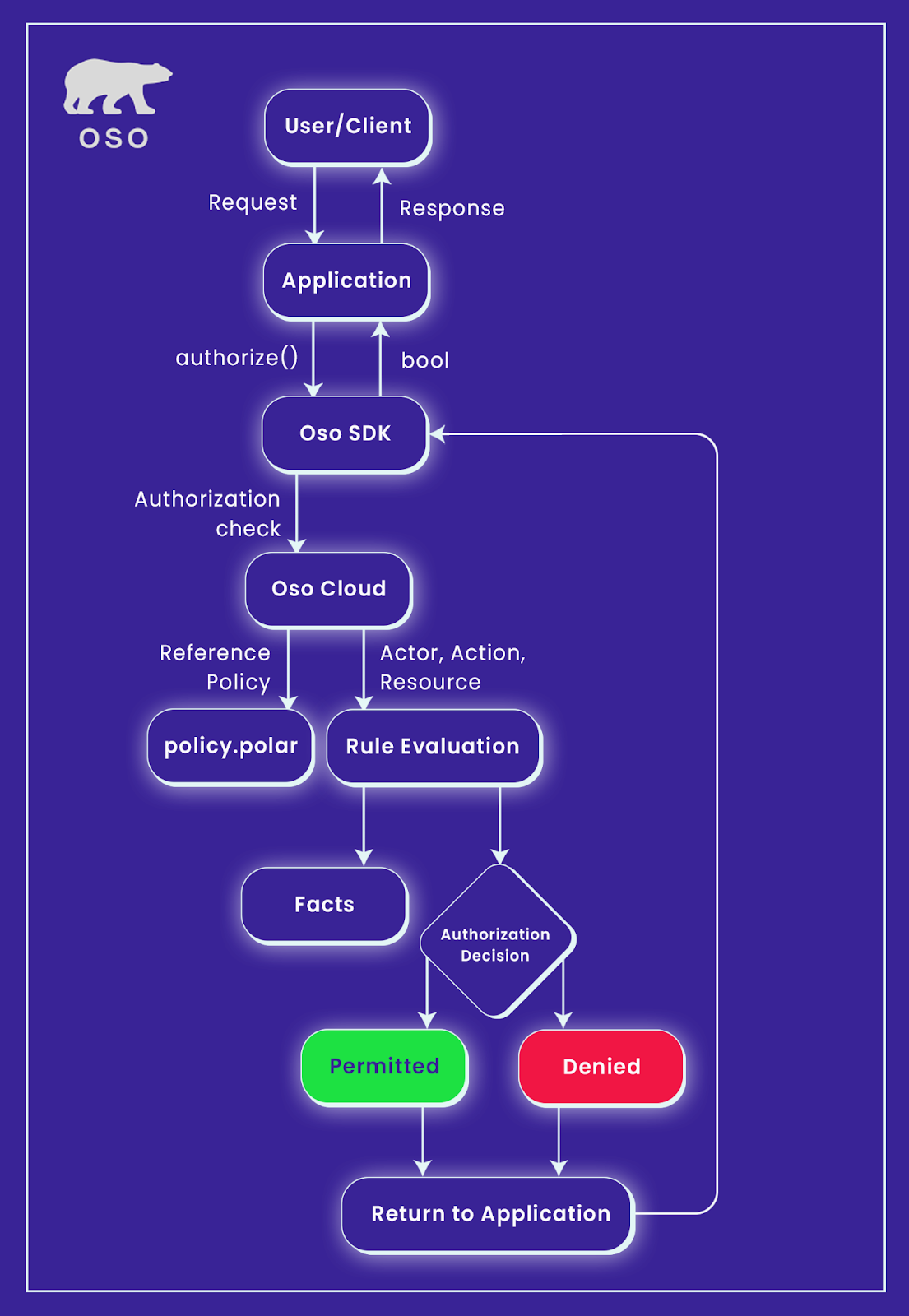
Here is the end-to-end flow of how Oso Cloud makes fine-grained authorization decisions in real-time across your stack:
User or Client Sends a Request: A user (human or machine) interacts with your app: e.g., trying to view a file, delete a project, or run a task.
Application Receives the Request: Your application captures this request and uses the Oso SDK to ask, “Is this user allowed to do this?” oso.authorize(user, action, resource)
Oso SDK Sends an Authorization Check: The SDK sends a query to Oso Cloud, including the actor (who’s asking), the action (what they want to do), the resource (what they want to do it to)
Oso Cloud Loads the Policy and Facts: Oso Cloud retrieves the .polar policy (your declarative access rules) and looks up any required facts (e.g., relationships, roles, attributes)
Rule Evaluation: The engine matches the incoming request (actor, action, resource) against the rules and facts using its logic engine.
Authorization Decision: If rules and context align, then permitted. If not, then Denied.
Response to Application: Oso Cloud returns a simple boolean: True is authorized, False if denied.
Application Responds to User: Your app proceeds accordingly, serves the page or data, or blocks the request with an error or warning.
Here’s a flow diagram explaining the complete flow of the authorization request in Oso Cloud:
How to Start Implementing Fine-Grained Authorization (FGA)
Getting started with FGA doesn’t require a full rewrite. The goal is to bring structure and flexibility to your existing access logic, one layer at a time.
1. Audit Existing Access Logic
Begin by identifying where access decisions currently happen, such as controllers, middleware, and database queries, and where they might be missing or inconsistent. This gives you a baseline for improvement.
2. Define a Base Policy (Start Simple)
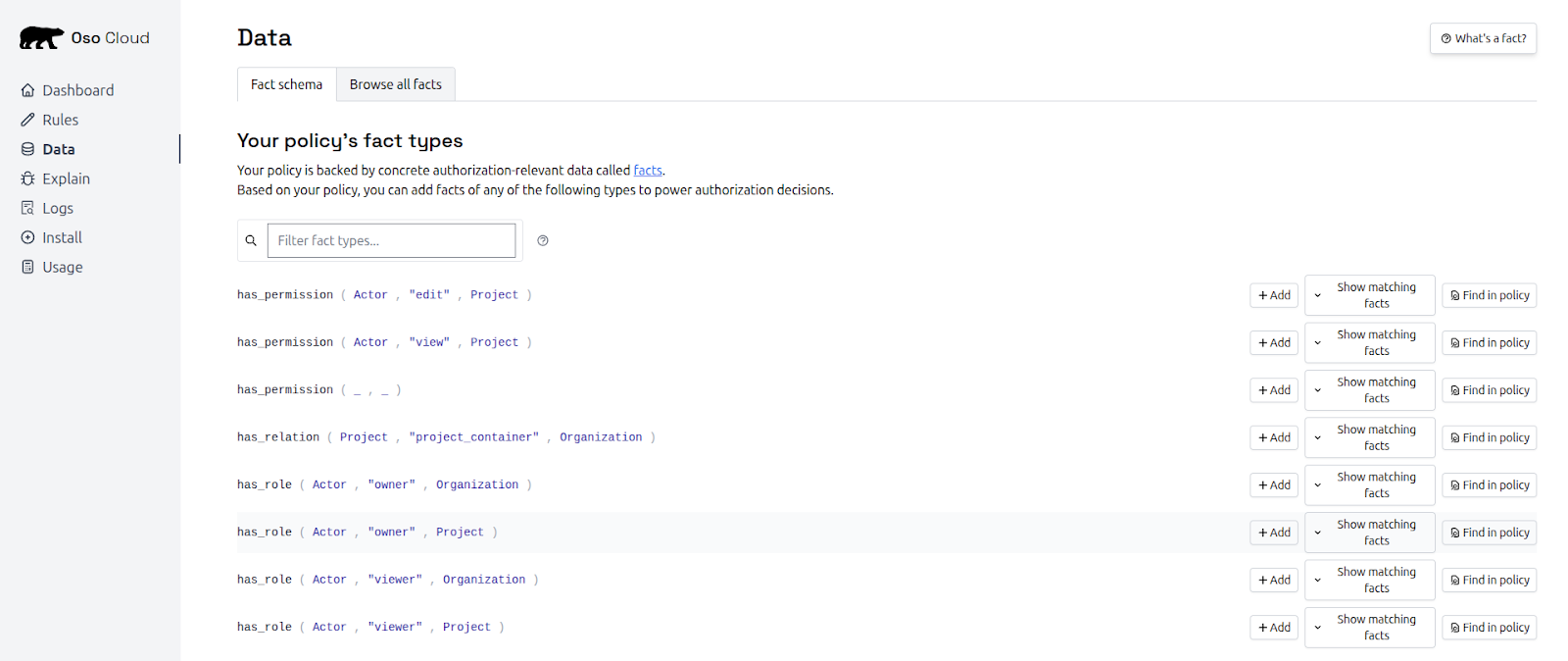
Start with clear, role-based, or relationship-based rules on a core resource. You can create the policies in Oso Cloud’s Data tab:
This creates a strong foundation before introducing complexity.
3. Add Attributes and Context
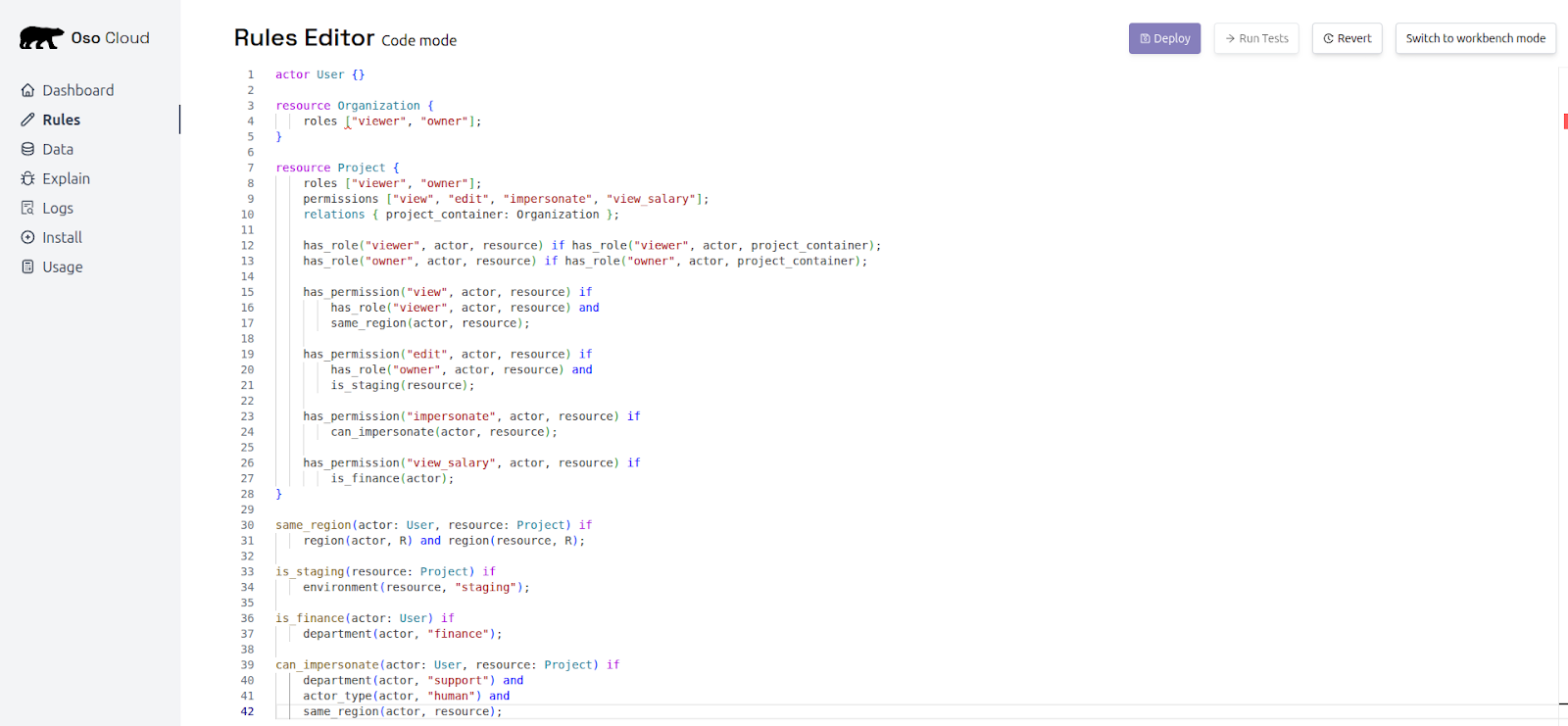
Extend rules with dynamic conditions like region, time, environment, or resource sensitivity in the rules editor. Here’s an example of fine-grained policy in the rules editor of Oso Cloud:
This is where your logic becomes fine-grained.
4. Use Oso as the Policy Engine
Once you have defined your policies, then use Oso SDKs or Oso Cloud to evaluate permissions across APIs, services, or agents without scattering logic everywhere.
5. Enforce at the Query and API Layer
Use built-in helpers like .authorized() with ORMs or apply authorize() calls directly in your backend to ensure data-level enforcement. Here’s an example express API calling authorize() function of the Oso SDK for authorization:
Treat authorization as code. Log denials, test rules, and track coverage so you can catch gaps early and gain visibility into access decisions.
Best Practices for Fine-Grained Authorization
Implementing FGA isn’t just about writing more rules; it’s about designing access logic that’s scalable, maintainable, and transparent. These best practices will help you get there:
1. Centralize Policy Logic
Don’t scatter access checks across files and services. Define policies once (e.g., in .polar or a central engine like Oso Cloud), and enforce them everywhere. This creates a single source of truth.
2. Keep Policies Readable
Write clean, expressive rules. Use meaningful names (e.g., has_role, is_owner), add comments for clarity and stick to consistent patterns across resources. Readable policies are easier to maintain and safer to update.
3. Decouple Policy from Code
Avoid hardcoding logic inside controllers or DB queries. Treat authorization as its own layer, separate from business logic, but deeply connected to it. This unlocks reusability across services and platforms.
4. Add Visibility and Logging Early
Log every denied access attempt, unexpected fallback, or override. This helps you debug faster, detect misconfigurations, and satisfy audit/compliance reviews. You can also add metrics around authorization outcomes (e.g., deny rates, top failing rules).
5. Monitor Edge-Case Failures
Watch for edge cases where rules don’t behave as expected. These often surface in unusual user states (e.g., temporary access), newly added roles or environments, and interactions between automation (bots/agents) and human permissions. Set alerts or write tests for known gotchas.
Policy Engine Triangle
🔺
Policy
/ \
Data -------- Enforcement
Policy: Your declarative rules (e.g., in Polar)
Data: Facts like roles, relationships, attributes
Enforcement: Where you apply the decision (API, DB, UI, etc.)
Access control used to be an afterthought, with a few if-statements here and a couple of roles there. That doesn’t cut it anymore.
With modern, distributed systems, especially those integrating AI and automation, authorization is core infrastructure. It affects everything from security and compliance to developer velocity and user trust. Fine-grained authorization isn’t just about “more” permissions. It’s about better ones that are more specific, more contextual, and more reliable across systems
Start using Oso Cloud to re-architect your stack to get there. Define once. Enforce everywhere. Scale securely.
FAQs
What Is the Difference Between Fine-Grained and Coarse-Grained Access Control?
Fine-grained access control offers detailed, specific permissions to resources or actions, while coarse-grained access control provides broader, less specific access, typically at the module or system level.
What Are the Two Types of Permissions?
The two main types are coarse-grained permissions, which use static roles like “admin,” and fine-grained permissions, which consider roles plus attributes, relationships, and context for more precise control.
What Is an Example of Fine-Grained Authorization?
A user can delete a project only if they created it, belong to the same department, and the project is still active, demonstrating role, relationship, and resource-based conditions.
What Is the Difference Between RBAC and FGA?
RBAC assigns permissions based on predefined roles, while FGA evaluates additional factors like user-resource relationships, attributes, and context to allow or deny access more precisely.
Zanzibar is Google's purpose-built authorization system. It's a centralized authorization database built to take authorization queries from high-traffic apps and return authorization decisions. An instance of Zanzibar hosts a list of permissions and responds to queries from many apps. Google published a paper on their global authorization system that they presented at 2019 USENIX Annual Technical Conference and it has since become a popular resource for developers who are building authorization services.
A Zanzibar instance is made up of a cluster of servers, a distributed SQL database, an indexing system, a snapshotting system, and a periodic jobs system.
This blog covers why Zanzibar was built and how it tackles the challenges of scaling authorization decisions, handling billions of objects, and ensuring low-latency, error-free results. Developers will learn about its architecture, including caching, replication, and consistency strategies, as well as the benefits and potential challenges of using a centralized authorization system, along with alternative services to such systems.
Abhishek Parmar, the creator of Google Zanzibar, is a technical advisor to Oso. Abhishek led the design, implementation and rollout of this service that is now used by Google's consumer and enterprise products.
You can read more about his work and perspective in this interview.
Why did Google develop Zanzibar for access control?
Google has many high-traffic apps, like Search, Docs, Sheets, and Gmail. Google accounts are shared between those systems, so authorization decisions (that is, what actions a Google account can take) need to be coordinated. These apps operate at huge scales, so constant inter-service communication isn't practical. Their authorization system needs to handle billions of objects shared by billions of users and needs to return results with very low latency. Also, their system needs to handle filtering questions, like "what documents can this user see?"
In short, their authorization system needs to be:
a. Error-free. An incorrect authorization decision might let someone see a document that wasn't meant for their eyes.
b. Fast. All other apps will be waiting on authorization decisions from Zanzibar. Google's target was <10ms per query.
c. Highly available. Authorization must be at least as available as the apps that depend on it.
d. High-throughput. Google handles billions of queries per day.
To learn more about Google Zanzibar permissions, read our interview with Abhishek Parmar, co-creator of Google Zanzibar.
How does Google Zanzibar solve for authorization?
Correctness
Zanzibar limits both user errors and system errors. To quote one of the designers, Lea Kissner, "The semantics in Zanzibar are very carefully designed to try and make it very difficult for you to shoot yourself in the foot." For a resource like a git repository, Zanzibar's API exposes who can see (or edit/delete/act upon) that repository, why they can see it, and how to stop it from being seen.
Zanzibar also limits system errors. Zanzibar authorization is a distributed system, which means it takes time to propagate new permissions. To avoid data staleness, Zanzibar stores permissions in Google's Spanner database. Spanner provides strong consistency guarantees, so Zanzibar never applies old permissions to new content.
Speed and availability
Zanzibar uses several tricks to reduce latency. First, it uses several layers of caching. The outermost cache layer is Leopard, an indexing system built to respond quickly to authorization checks. Then, read requests are cached across the servers that store permissions. Also, calls between services inside Zanzibar are cached.
Secondly, Zanzibar replicates data to move it closer to its physical access point. This system works like a CDN—Google maintains many instances of Zanzibar throughout the world.
On top of that, Zanzibar relies on some hand-tuning. In any authorization policy, some common permissions are used far more often than others. Zanzibar's team hand-tunes these hot spots, for instance by enabling cache prefetching.
Scale
With Zanzibar's replication and caching, it can store trillions of access control rules and handle millions of requests per second.
What does Google Zanzibar do well?
Zanzibar is a centralized source of authorization decisions. That can be a useful approach for two reasons. First, it is a single source of truth. Each of your services can call Zanzibar and get a "yes" or "no" answer in response, and those answers are consistent between services. Second, each of those services calls the same API, which makes it easier to use across many services.
Zanzibar also supports reverse indexing (also known as data filtering). This means that after assigning a user many individual permissions, you can also ask, "what resources does this user have access to?" This is a common authorization request (e.g., for list endpoints). It's also useful for maintaining and debugging access controls.
What doesn't Google Zanzibar do?
A Zanzibar-like solution requires centralizing all authorization data in the solution. This includes obvious things like roles, but it also encompasses org charts, file and folder hierarchies, document creators - anything you may ever use in an authorization query. The problem is that you also need that data in your application, so you have to duplicate it between the two. Google has the culture to impose this requirement and the resources to support it, but most companies don’t. We talk about our own experiences with data centralization and how we relieve this tension in our post on Local Authorization.
The overlap between application data and authorization data
Zanzibar provides few abstractions to work with. Its authorization logic is a flat list of access controls. You can define relationships between users and resources, but you can't use properties of resources (like public/private switches) to make authorization decisions. It’s up to you to work out how to represent whatever authorization model you may have as a set of relationships. Google's engineers recommend that you use a policy engine alongside Zanzibar to close the gap.
Finally, Zanzibar is a major technical investment. Building your own Zanzibar takes at least a year of effort from a dedicated team. Airbnb's Himeji (a Zanzibar-alike) took more than a year of engineering work from a dedicated team.
Using Zanzibar also takes engineering effort. At Google, the service is supported by a full-time team of engineers, plus several engineers from each service that uses Zanzibar. Most apps that use Zanzibar-like systems require hand-tuning to avoid hot spots.
Looking for an authorization service?
Engineering teams are increasingly adopting services for core infrastructure components, and this applies to authorization too. There are a number of authorization-as-a-service options available to those who want something like what Google made available to its internal engineers via Zanzibar.
Oso Cloud is a managed authorization service that provides the benefits of Zanzibar while filling in a number of Zanzibar’s gaps. You use Oso Cloud to provide fine-grained access to resources in your app, to define deep permission hierarchies, and to share access control logic between multiple services in your backend.
Oso is built for application authorization. It comes with built-in primitives for patterns like RBAC and ReBAC, and it is extensible for other use cases like attribute-based access control (ABAC). It is built using a best practices data model that makes authorization requests fast and ensures that you don’t need to make schema changes to make authorization changes. It provides APIs for enforcement and data filtering. Oso Cloud is also deployed globally for high availability and low-latency.
Fun fact: Abhishek Parmar, one of the co-creators of Google Zanzibar and Airbnb Himeji, is a technical advisor to the Oso engineering team.
Oso Cloud is free to get started – try it out. If you’d like to learn more about Oso Cloud or ask questions about authorization more broadly, come say hi to us on Slack.