
Every week I meet with engineering teams working on authorization. Even though everyone is trying to solve the same problem, no two teams think about it the same way. My goal is to meet engineers where they are. I want to help bridge their mental models to the authorization models that most resemble them. To this end, I recently helped generalize the data model of Oso Cloud, our authorization-as-a-service platform, to make it flexible enough for anyone to express their mental model then write an authorization policy over it.
While this change made Oso Cloud more expressive and flexible, I was surprised to see customers – and even our own engineers – start to make new, unexpected mistakes. This post describes how I fixed that with type inference.
The Problem
A fact in Oso Cloud is a combination of a predicate name and a list of arguments in the form of type-identifier pairs; for example, has_role(User:bob, String:writer, Document:blog_post). A policy then describes how facts determine authorization decisions. For example this fact together with the following policy would mean that Bob is authorized to edit the blog post document:
actor User {}
resource Document {
roles = ["writer"];
permissions = ["edit"];
"edit" if "writer";
}
V1 of Oso Cloud accepted so few formats of information that there was a dedicated API specifically for writing role information. You could tell Oso Cloud the fact that Bob is a writer of the blog post document with the CLI command oso-cloud add role User:bob writer Document:blog_post. This API would scan your policy to see what roles are declared on the type you’re adding a role to, and would only add the role if it matches one of them; otherwise it would show an error. This way if you tried something like oso-cloud add role User:bob qriter Document:blog_post, the CLI would show you an error indicating that you made a typo.
The new data model generalizes the API to arbitrary facts, as opposed to the select few like has_role that were previously supported. Allowing arbitrary facts makes Oso Cloud expressive enough to support more modeling paradigms. One example is the concept of marking a resource as public using a predicate named is_public with one argument:
has_permission(_: User, "read", doc: Document) if
is_public(doc);
If you then tell Oso Cloud that the “readme” document is public by doing oso-cloud tell is_public Document:readme, then Oso Cloud will allow all of your users to read the readme document. Note that is_public is an arbitrary name that doesn’t mean anything special to Oso, and the policy is all that defines the meaning of is_public.
Since facts came to have arbitrary user-defined meanings like this, we could no longer validate facts like we used to. If you made a typo like oso-cloud tell has_role User:bob qriter Document:blog_post, Oso Cloud would successfully save this useless fact, rather than noticing that you probably meant to spell “writer”.
In the weeks after we released the new data model, this problem grew apparent. I observed that customers and sometimes even our own employees would make mistakes such as:
- Incorrectly capitalizing names of roles/relations/permissions
- Forgetting to include the fact’s predicate name
- Forgetting to include one of the fact’s arguments
- Referring to an undeclared or misspelled type
One time in a meeting with a potential customer we recognized that a big part of their authorization model resembled custom roles, a paradigm made possible in Oso Cloud by the new data model. One of us shared our screen and did a live demo writing a policy and facts using custom roles to solve the specific problem the customer described.
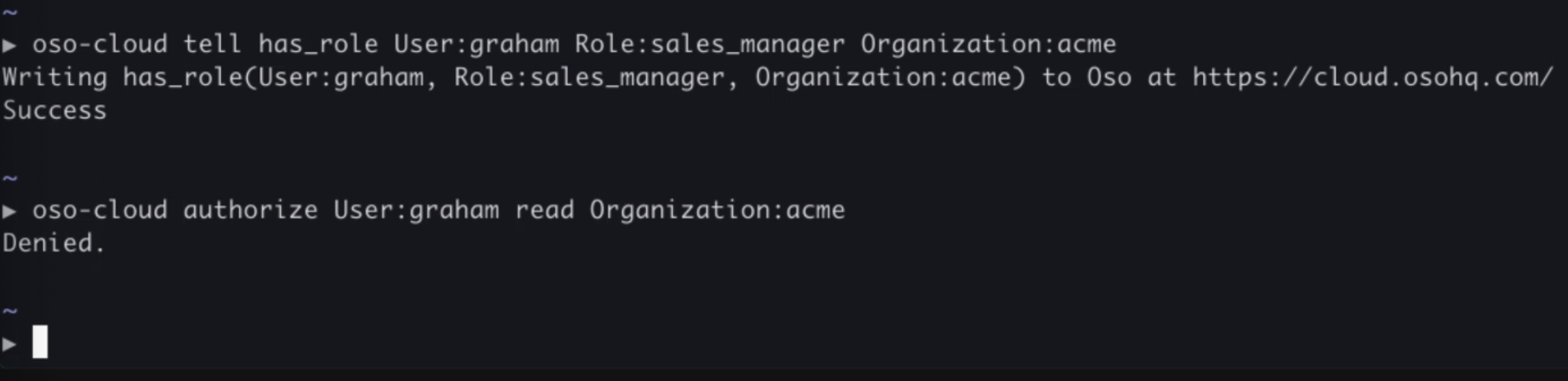
In the punchline of the demo, when everything was supposed to come together and result in successful authorization, the request was denied. None of us caught what went wrong until afterwards.
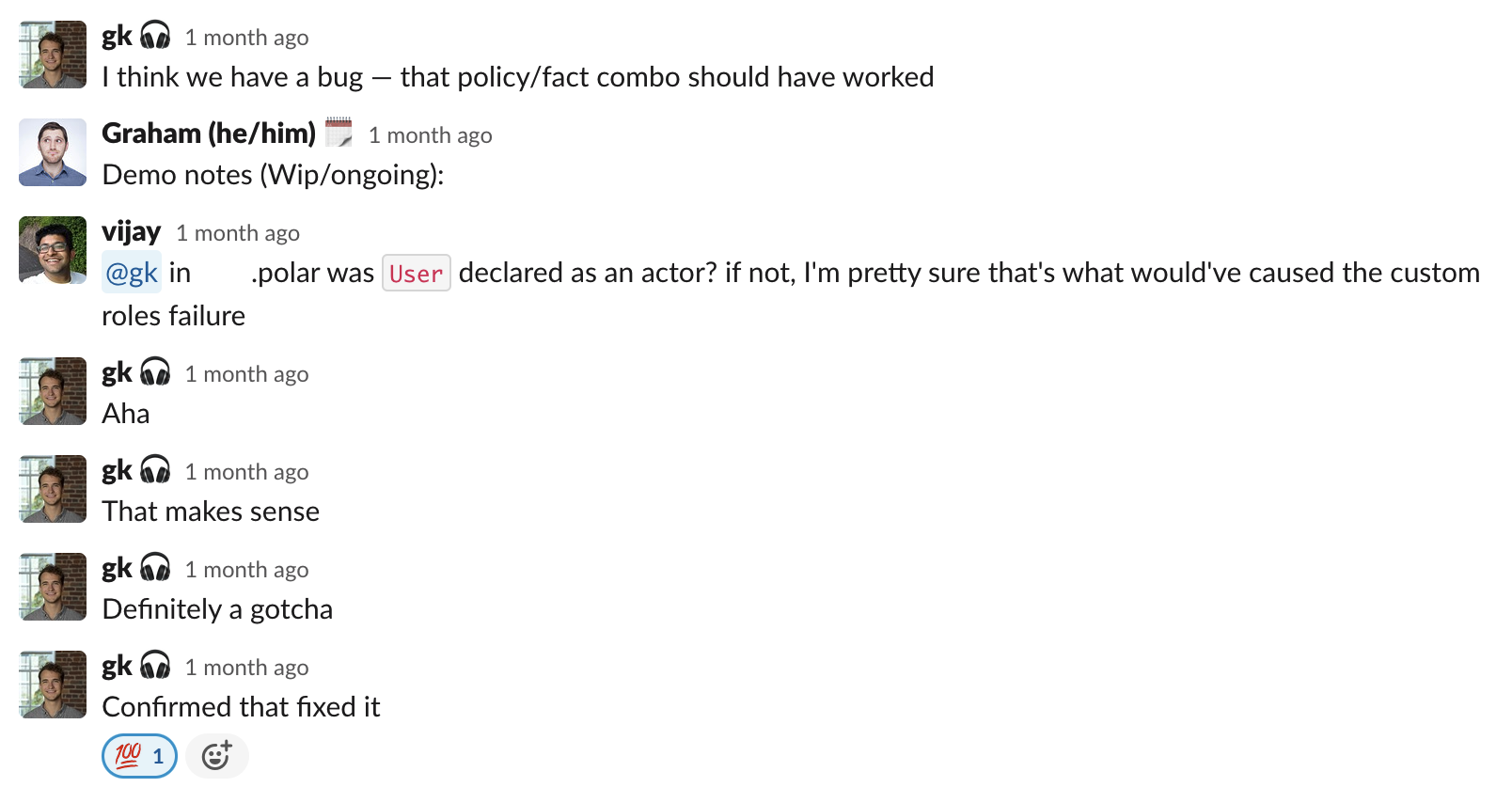
We had forgotten to declare the User type in the policy, and this mistake was not surfaced to us when we added facts about Users.
Experiences like this made it clear to us that we had to bring back some form of validation for facts. But how?
Pruning the User’s Decision Structure
 Image credit: The Psychology of Everyday Things, Donald A. Norman, page 120
Image credit: The Psychology of Everyday Things, Donald A. Norman, page 120
In The Psychology of Everyday Things, Don Norman observes that activities that humans tend to be error-prone with are “[t]hose with wide and deep structures, the ones that require considerable conscious planning and thought, deliberate trial and error: trying first this approach, then that—backtracking.” The structure he refers to represents the actions that a user may take. The more actions that are available at any given point in time, the wider the structure; and the more steps it takes to complete the task from start to finish, the deeper the structure.
Viewing the situation through this lens gives us an answer to both what went wrong in the first place, and a way to think about fixing it. Take as an example the task of getting up and running with Oso Cloud by writing some test facts and performing some authorization queries against them. When we generalized the data model, we increased both the width and depth of the structure of interacting with Oso Cloud. The new structure lets you write facts that don’t bring you closer to your goal of affecting a subsequent authorization query. After receiving an unexpected result, you need to backtrack to figure out and fix the mistake you made — if you have the patience for it.
Given any particular policy, some facts will obviously never affect the result of an authorization query. If we make it impossible to input facts like that, then we can eliminate many of the unnecessary actions the user could take. This would make the structure of interacting with Oso Cloud more narrow and shallow. For this reason, it made sense to adopt the guiding principle: “reject any fact that we know cannot affect an authorization decision”.
What Didn’t Work
I considered many approaches before settling on one that worked.
Hardcoding Checks
One naive solution could have been to hardcode validation in some cases when the predicate of the fact matches certain values. For example, when we receive a fact with the name has_role, we could validate it with the logic that we used to use in the old add role API; check the list of roles declared for the particular type, and only accept the fact if the role matches one of them. There are a few problems with this approach.
First, if someone writes a policy that defines the has_role predicate to have a different meaning than the one prescribed by this validation, then we would reject facts for no good reason.
# example: giving has_role a different meaning.
# Hardcoded validation would unnecessarily reject
# has_role facts that have 1 argument.
has_permission(actor: Actor, "wield_role", _: Organization) if
has_role(actor);
Second, this style of validation wasn’t even complete in the first place. It doesn’t recognize roles that are declared outside of designated resource blocks.
# example: declaring a "superadmin" role outside of resource blocks.
# Hardcoded validation would unnecessarily reject the superadmin role.
resource Repository {
roles = ["reader", "maintainer"];
...
}
has_permission(actor: Actor, _: String, repo: Repository) if
has_role(actor, "superadmin", repo);
More fundamentally, granting specific predicate names specific meanings in this way is user-unfriendly. It makes the language harder to use and maintain as users would need to be intimately familiar with the data validations they’re opting into when using certain predicate names. It also contradicts the philosophy of generalizing the data model in the way that we did, as people who use custom predicates would not get the benefits of fact validation.
Declaring Types
Another potential solution was to introduce a syntax for declaring types of predicates, similar to the declare syntax that languages like TypeScript and Flow have. We could make it lightweight by having resource block syntax implicitly emit these declarations.
resource Repository {
roles = ["reader", ...];
...
}
# implicitly desugars to
declare has_role(Actor, String, Repository);
We could use these declarations to check that facts are used with the correct number of arguments and with the correct types. One benefit of this approach is that it would allow users to opt into fact validations for their own custom predicate types by explicitly writing type declarations.
declare is_public(Document);
has_permission(_: User, "read", repo: Document) if
is_public(repo);
We considered a “strict mode” where Oso Cloud would reject any fact that did not have a type declared in the policy.
One drawback of this approach was that it would be hard to use it to achieve validation fine-grained enough to, for example, check that role names are spelled correctly. In this formulation, it would not be able to catch the typo in a request like oso-cloud tell has_role User:bob qriter Document:blog_post. In order to catch something like that, we would have to design a more complex type system with string literals and unions. That way, a role could be expressed by a type like "writer" | "reader" which is inhabited by some strings but not by all strings. This is further complicated by the fact that some roles are valid on some resources but not others. For example, “maintainer” is a role that tends to apply to things like repositories but not to things like organizations. So we may also need to introduce a concept like type intersection so that has_role can have a type like has_role(Actor, "writer" | "reader", Document) & has_role(Actor, "writer" | "reader" | "maintainer", Repository).
Type systems with that level of complexity exist, but it’s a level of complexity that we do not want to add. The goal is to make it easier to adopt Oso, and adding a type system like this would have the net effect of making Oso Cloud harder to use by giving users more to grok.
So far we’ve found that the constraints that we use to validate facts have to account for all rules defined in the policy (not just resource blocks), and also that we don’t want our users to have to wrangle with a type system themselves. This calls for validations that are automatically derived from the policy code in a way that the user doesn’t have to get involved in, but that at the same time make sense to the user. This calls for “type inference.”
What Worked: Type Inference
Before type theory purists come after me like my friend did back in college (see screenshot), I want to say that I use the term “type inference” lightly.

I originally wanted to avoid implementing any form of type inference in Oso Cloud, as it has potential to get unwieldy in the same way that designing a user-facing type system would have gotten. After considering alternatives and mulling on the design for a bit, I came up with something that achieves the level of granularity we want in fact validation, with minimal user-facing overhead. It’s a simple algorithm that analyzes policy code and infers types. I’ve managed to avoid it needing to deal with concepts that some other type theorists may expect a type inference algorithm to need, like parametric polymorphism, polarity, and binding structure.
Use-Based Type Inference
Recall that we want to reject any fact that can not affect an authorization decision. We can use this principle together with the execution model of Oso Cloud to determine how we may infer how to validate facts.
Oso Cloud will never apply a rule to a fact when the types don’t match. Consider the following policy:
foo(x : A) if
bar(x);
If Oso Cloud has been told the fact bar(A:1), then it will conclude that foo(A:1) is also true. However, if Oso Cloud has only been told the fact bar(B:1), then it will never apply this rule to that fact because the type B does not match the type A. If this rule is the only way in which bar is used throughout the policy, then we know that we only need to accept bar facts where the type of the argument is A, and we can give the user an error on all other types. We effectively infer the type bar(A).
We can apply the same concept when predicates are used with specific strings. This is particularly useful for predicates like has_role. Consider the rule:
has_permission(actor: Actor, "read", doc: Document) if
has_role(actor, "reader", doc);
This is a very common pattern in Oso Cloud policies. If this is the only way has_role is used in the policy, we can safely infer the type has_role(Actor, "reader", Document) and reject any fact that does not have the value "reader" as the second argument.
The next question is how to combine types when a predicate is used multiple times. For example, consider a policy with two rules:
has_permission(actor: Actor, "read", doc: Document) if
has_role(actor, "reader", doc);
has_permission(actor: Actor, "push", repo: Repository) if
has_role(actor, "maintainer", repo);
A first attempt at a solution may be to union together the types of the arguments. In this case, that would yield the type has_role(Actor, "reader" | "maintainer", Document | Repository). However this approach is unnecessarily permissive. It would allow for writing a fact like has_role(User:bob, "maintainer", Document:blog_post), even though with this policy it is meaningless to be a maintainer on a document. This fact would never be used in an authorization decision.
Rather than unioning together argument types across uses of a predicate, we simply collect a list of all the ways that the predicate is used in the policy. In this case, it would look like has_role(Actor, "reader", Document) & has_role(Actor, "maintainer", Repository). When you tell a fact to Oso Cloud, it checks it against all the ways that the predicate is used in your policy. If the fact matches any of the uses, we accept the fact; otherwise, we provide an error describing why the fact doesn’t make sense.
Try it out!
I shipped this approach for data validation less than a month ago and I’ve already witnessed several instances of it catching typos when interacting with Oso Cloud. I like it for the same reason that I like using continuous integration and statically typed languages; it’s nice when tooling catches your mistakes sooner than later. Walking this line between making Oso Cloud powerful and easy to use is one of our main focuses as an engineering team. Solutions like this remind me that the line isn’t always so fine – with the right mindset and some iteration, we can do both.
Try using Oso Cloud! Write a policy and see what facts our type inference algorithm will let you input!
