
No one seems to agree on best practices for authorization in microservices (aka service-oriented backends). I've spoken with teams who append user roles onto authentication tokens, teams that store everything in authorization-specific graph databases, and teams that perform authorization checks automatically in Kubernetes sidecars. Months or years of engineering work has gone into these solutions, and each team invents its own wheel.
How do you handle authorization in microservice architecture?
In this blog post, we recommend three best practices (or patterns) for handling authorization data in microservices.
- Leave the data where it is, and have services ask for it directly.
- Use a gateway to attach the data to all requests, so it's available everywhere.
- Centralize authorization data into one place, and move all decision making to that place.
When you have a monolith, you generally only need to talk to one database to decide whether a user is allowed to do something. An authorization policy in a monolith doesn't need to concern itself too much with where to find the data (such as user roles) — you can assume all of it is available, and if any more data needs to be loaded, it can be easily pulled in from the monolith's database.
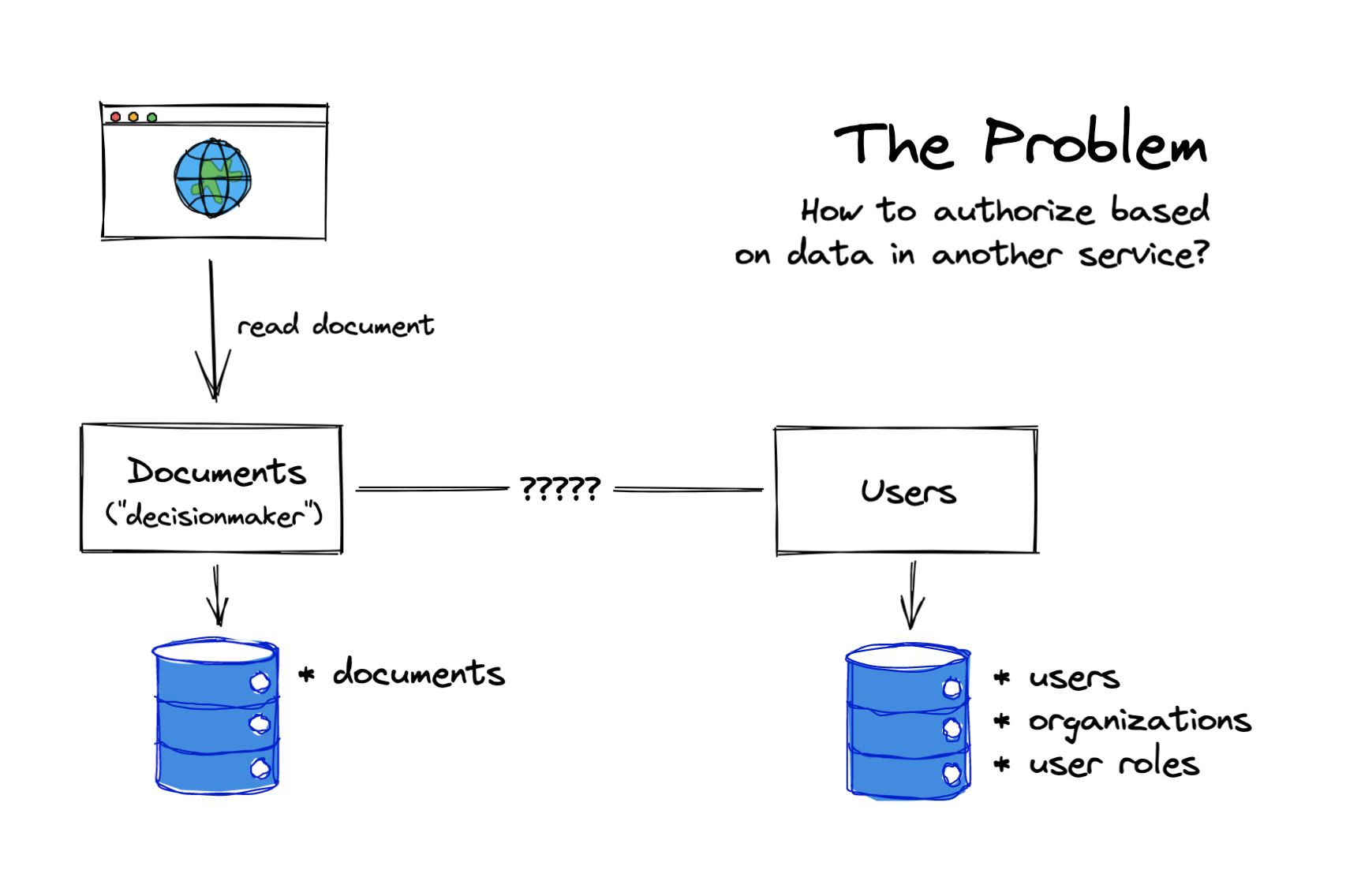
But the problem gets harder with distributed architectures. Perhaps you're splitting your monolith into microservices, or you're developing a new compute-heavy service that needs to check user permissions before it runs jobs. Now, the data that determines who can do what might not be so easy to come by. You need new APIs so that your services can talk to each other about permissions: "Who's an admin on this organization? Who can edit this document? Which documents can they edit?" To make a decision in service A, we need data from service B. How does a developer of service A ask for that data? How does a developer of service B make that data available?
We’ll walk through each of the patterns above, along with the pros and cons of each approach.
Why is authorization harder within a microservices environment?
Let's take an example authorization scenario, an app for editing documents. It's trivial but hopefully illustrative:
- There are users, organizations, and documents.
- Users can have roles within organizations, either
memberoradmin. - Documents belong to organizations.
- A user can read a document if she has a
memberrole on the organization. - A user can read OR edit a document if she has an
adminrole on the organization.
In a monolith, it's not too hard to express that logic in a clean way. When you need to check whether a user can read a document, you check which organization the document belongs to, you load the user's role for that organization, and you check if that role is one of member or admin. Those checks might require an extra line or two of SQL, but the data's all there.
What happens when you've split your application into different services? Perhaps you've peeled off a new "documents service" — now, checking read permission on a particular document requires checking user roles that live outside of that service's database. How does the document service access the role data that it needs?
Microservice Authorization Pattern 1: Keep the data where it is
Often the simplest solution is to keep the data where it is and have the services ask for the data that they need, when they need it. You might see this as the most obvious solution given the problem outlined above.
You split up your data model and logic such that the documents service controls which document-related permissions are granted by which role (admins can edit, members can read, etc), and then the users service exposes an API to grab a user's role on an organization. With this API in place, the permission check can happen like so:
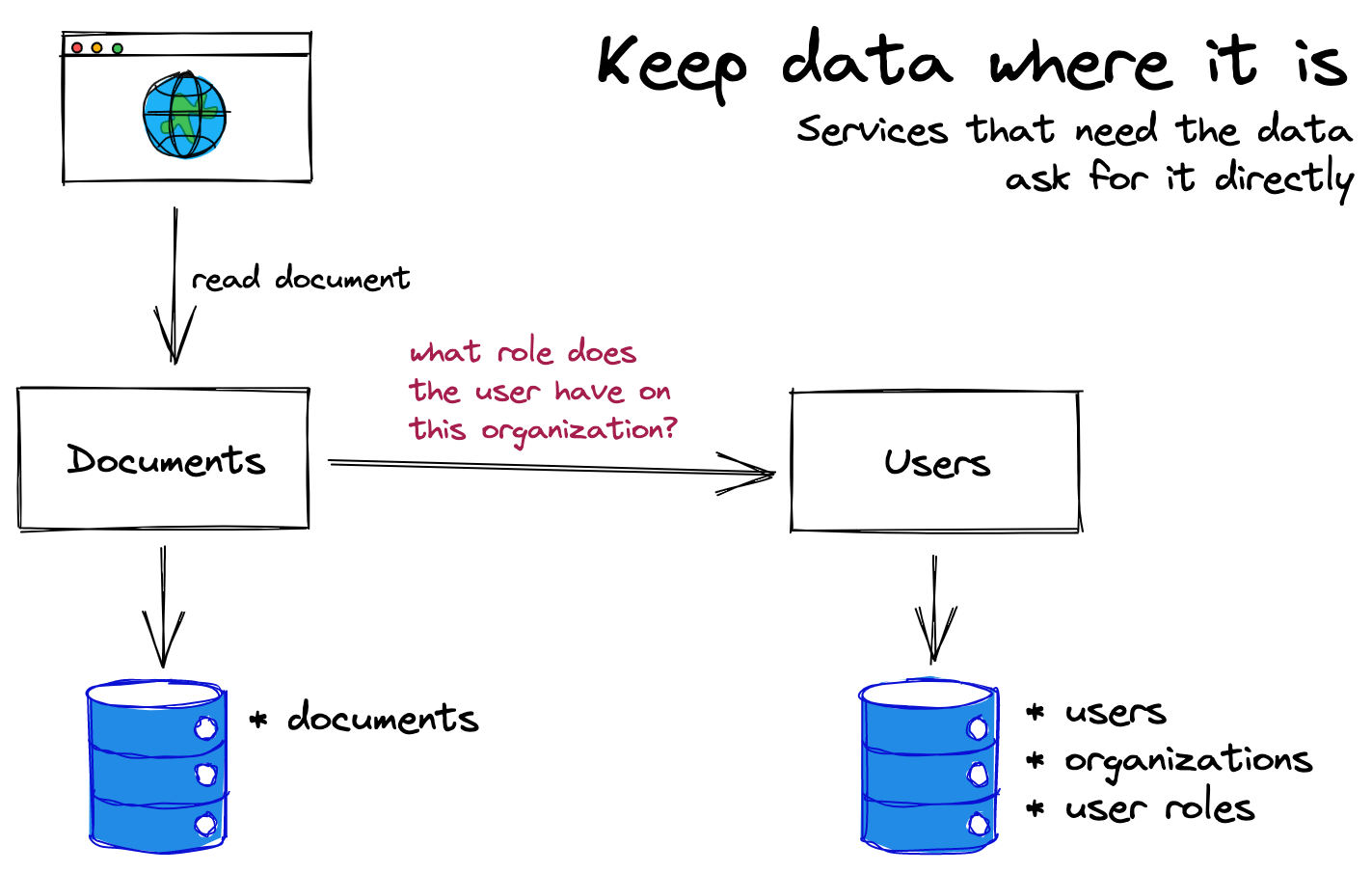
There's a reasonable argument that the simplest solution is the best solution, and that often applies here. In my experience, this is generally where teams land when they're starting to move to microservices and just want to get something working. It gets the job done, and doesn't require any extra infrastructure.
This pattern begins to show cracks when the numbers of services or teams grows, when authorization logic gets more complex, or when facing more strict performance requirements. To make this work, developers of any new services need to know how to fetch role data from the users service, which itself has to scale to meet that demand. As service dependencies proliferate, the pattern can add unpredictable latency and duplicate requests. Perhaps the introduction of a separate "folders" service makes permission checks into a web of chatter between services:
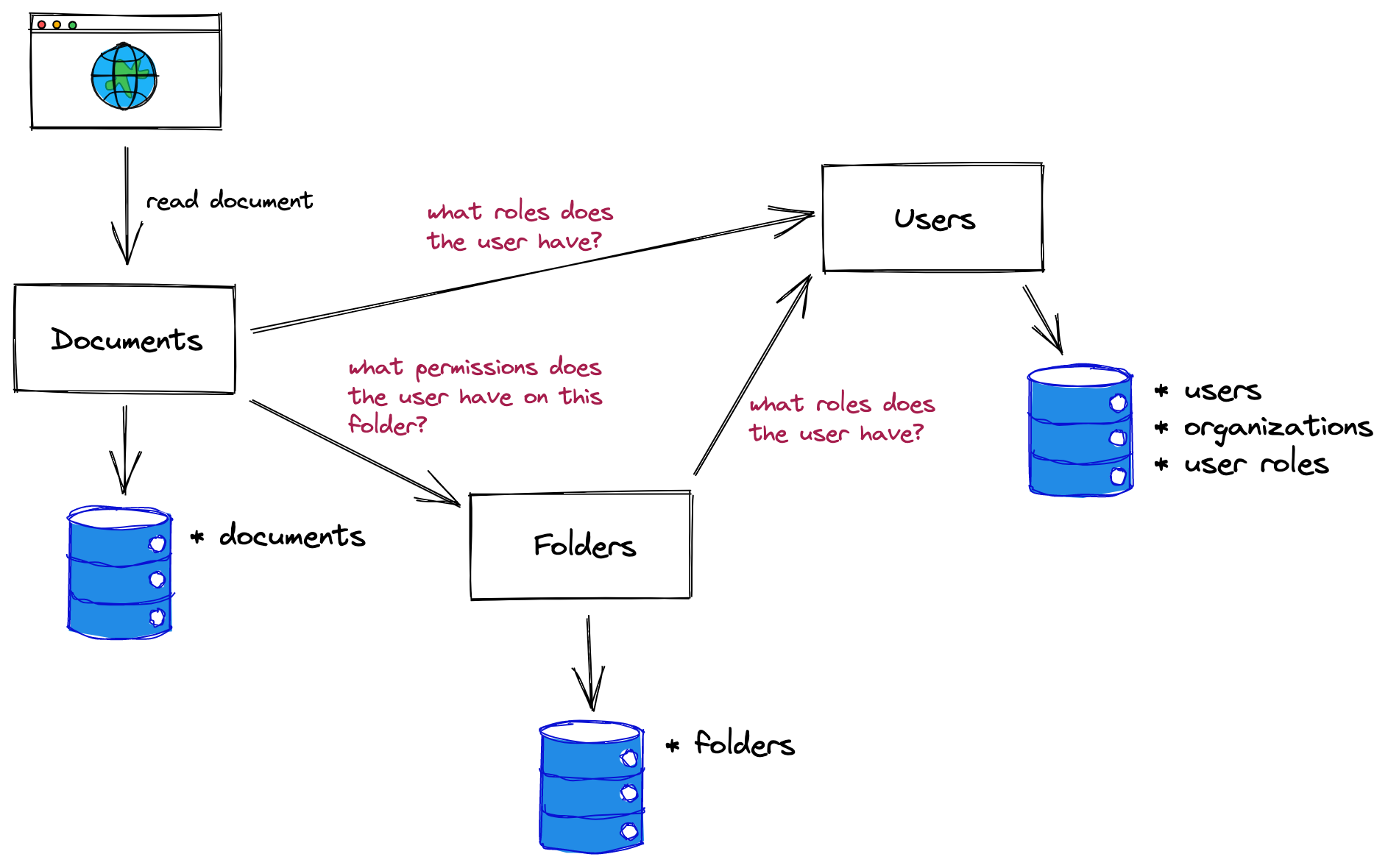
Despite its risk of becoming a bit disorganized, this pattern can get you pretty far. Not having to deploy and maintain an extra piece of infrastructure for authorization can be a huge advantage, and if the services with data can handle the load from services that need the data, then stringing them together is a fine solution.
I've talked to a few teams who've followed this general pattern but feel like they should replace all the piping with some kind of dedicated authorization service. I always make sure to ask what their real problem is. If it's latency, perhaps adding a cache in the right place will solve it. If it's that the authorization logic is growing disorganized in the services themselves, then perhaps you need to impose a standard policy format. (Oso is one solution to that; there are others too.)
But if the problem is that your data models are becoming too complex, or that you're re-implementing the same APIs repeatedly, or that permission checks require talking to too many different services, then perhaps it's time to rethink the architecture.
Microservice Authorization Pattern 2: A Request Gateway
One clean solution to the authorization data problem is to include a user's roles in any request to all services that might need to make a decision. If the documents service gets information about the user's role as a part of the request, it can make its own authorization decisions based on that.
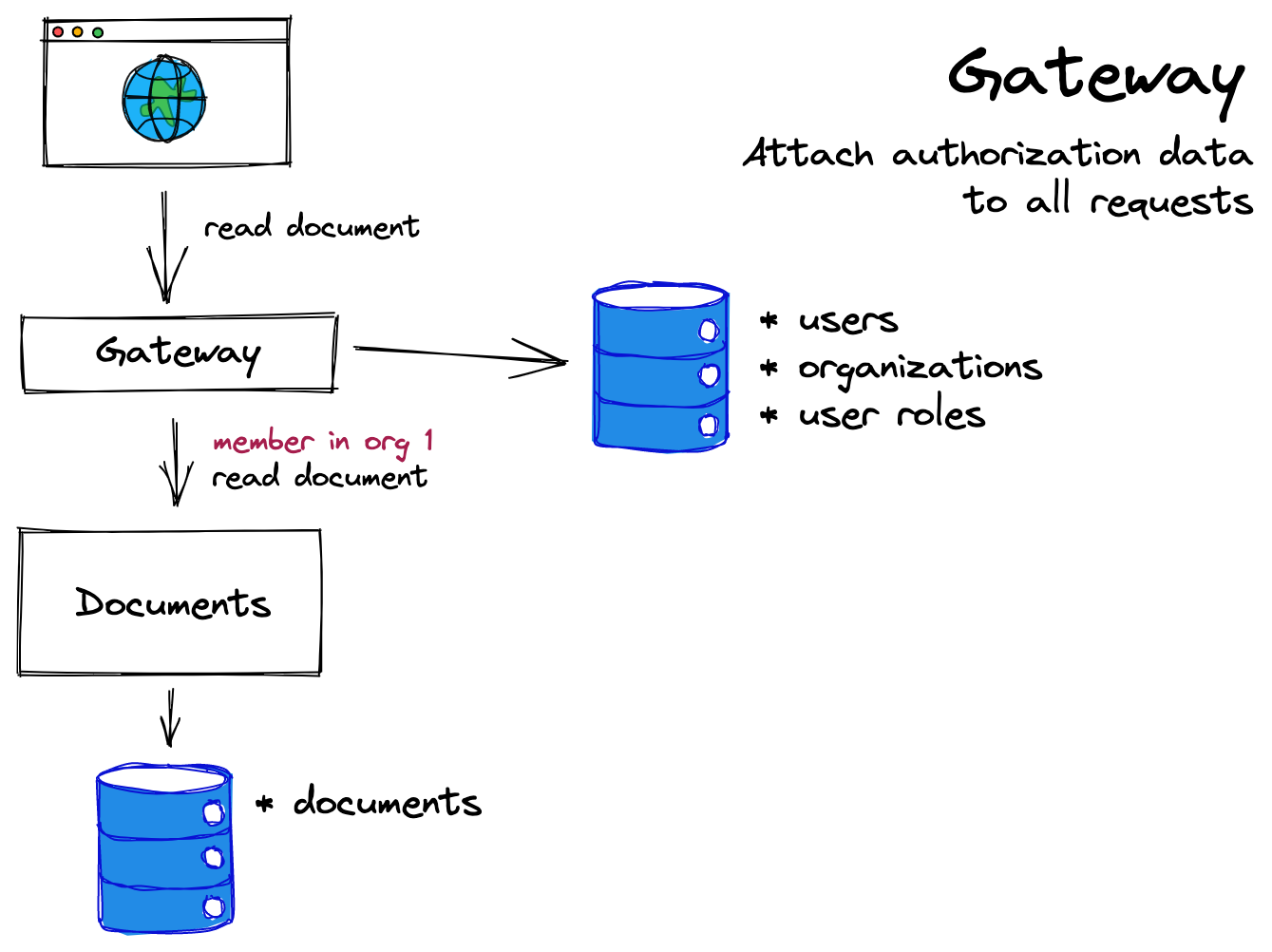
In this pattern, a "gateway" sits between an API and its end-user. The gateway has access to user information and role information, which it can attach to the request before it passes it on to the API itself. When the API receives the request, it can use the role data from the request (i.e. in its headers) to check that the user's action is allowed.
It is common for the gateway to be responsible for both authentication AND authorization. For example, the gateway might use an Authorization header to authenticate a particular user, and then additionally fetch that user's role information. The gateway then proxies the request with user ID and role information to a downstream service (the documents service in the example above).
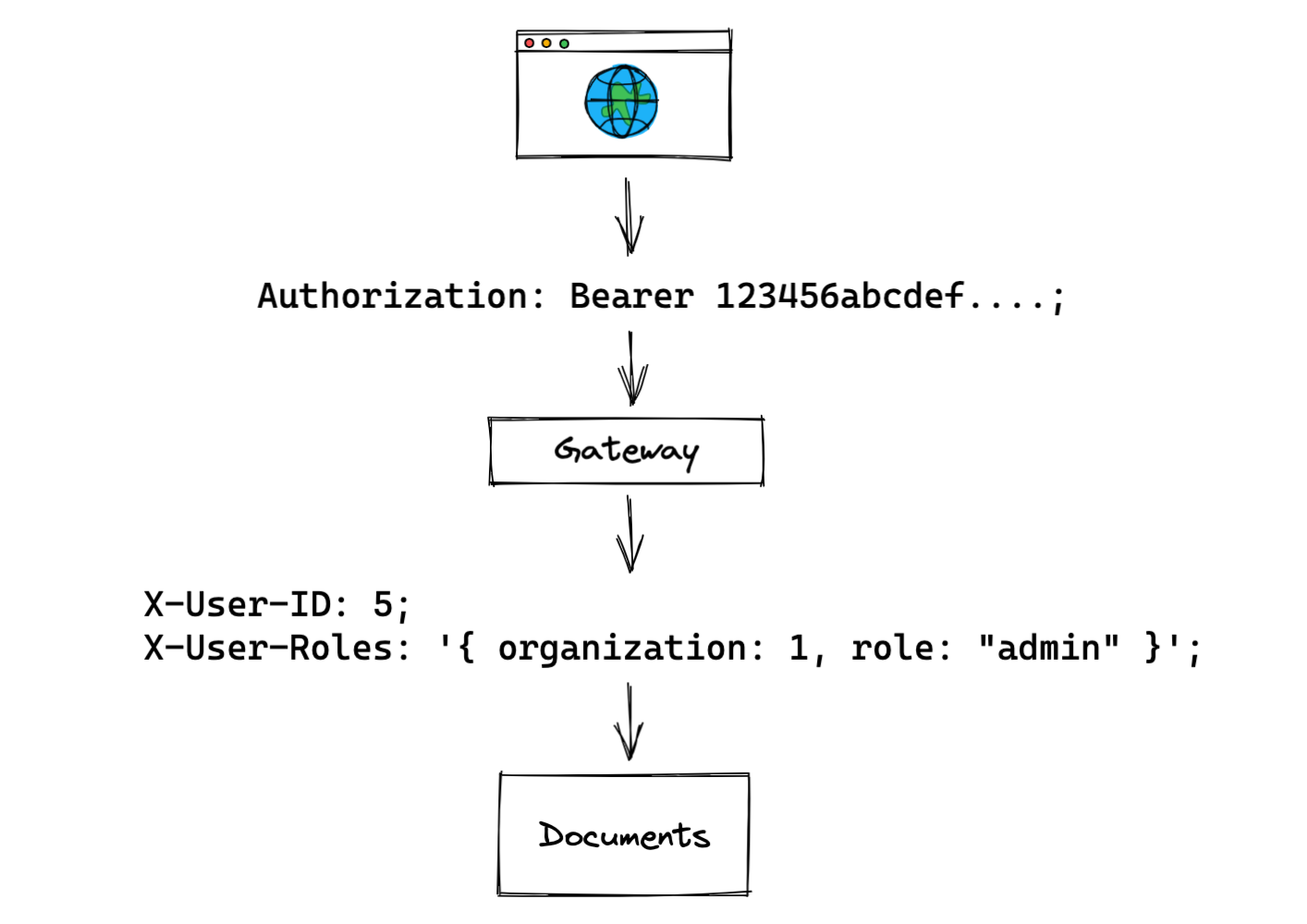
The main benefit of the gateway pattern is its architectural simplicity. It allows developers of downstream services (like the documents service) not to care about where roles data is coming from. The authorization data is always available on the request — a permission check can be performed immediately without any additional round-trips.
Note that using bare headers here does open up new avenues of attack — you'd need to make sure that malicious clients cannot inject their own headers. As an alternative, a user's role or other access control data can be included in their authentication token itself, often expressed as a JWT.
Gateways work best if your authorization data consists of a small number of roles (for example, every user can have just one role at one organization). When permissions start to depend on more than just a user's role in an organization, the size of the request can explode. Perhaps a user can have different roles depending on the type of resource they are trying to access (an organizer of a particular event, or an editor on a particular folder). Sometimes this data is simply too big to reasonably fit in a header, and other times it's inefficient to fetch all that data eagerly. If this is the case, stuffing all relevant authorization data onto a token or into a header doesn't quite cut it.
Microservice Authorization Pattern 3: Centralize all authorization data
Another solution is to put all authorization data and logic into one place, separate from all the services that need to enforce authorization. The most common way to implement this pattern is to build a dedicated "authorization service." Then, when your other services need to perform permissions checks, they turn around and ask the authorization service:
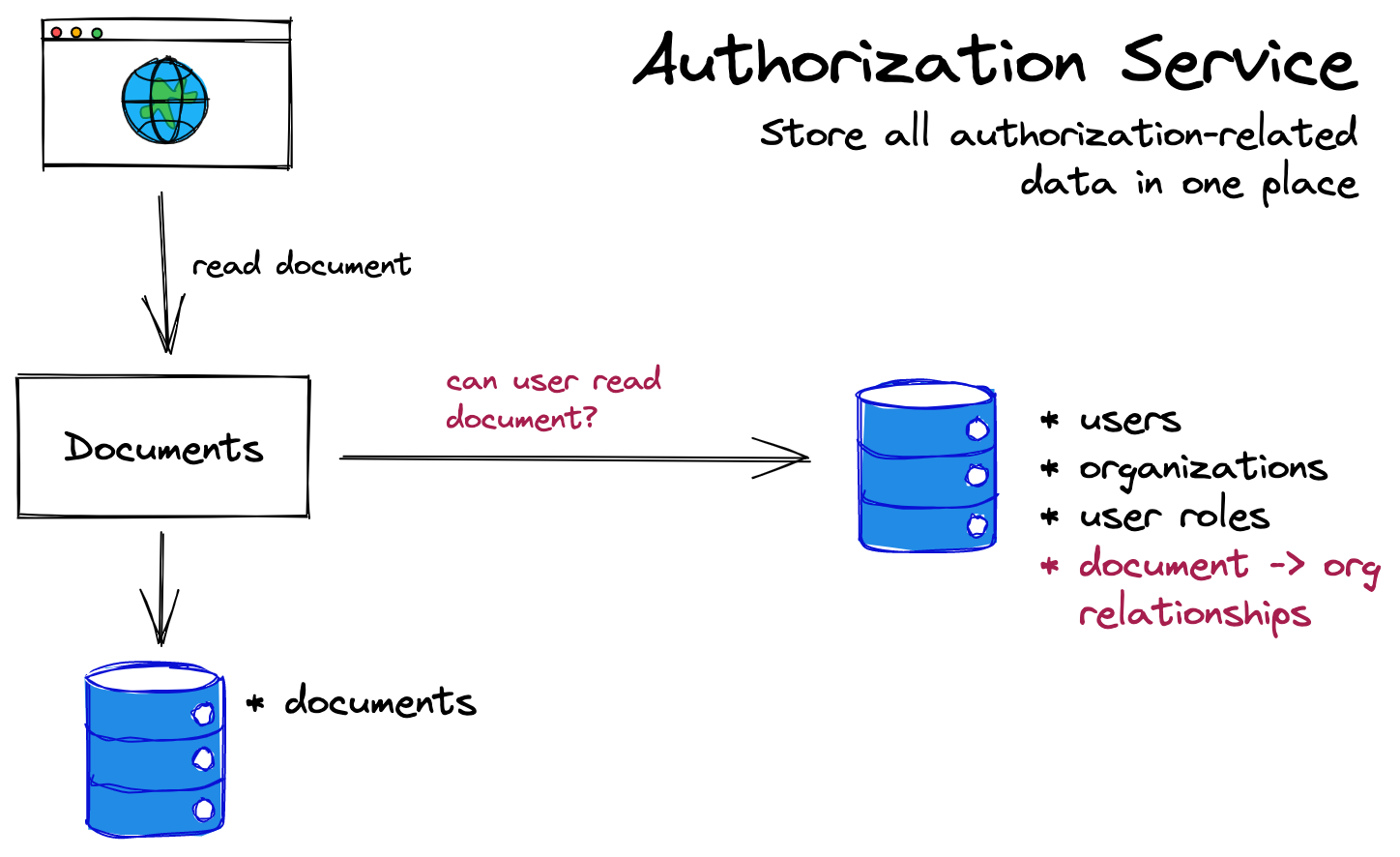
In this model, the documents service doesn't care about the user's role at all: it just needs to ask the authorization service whether the user can edit a document, or whether a user can view a document. The authorization service itself contains everything it needs (including role data) to make that decision.
This can be quite appealing: you now have one system in charge of authorization, which fits with the philosophy of microservices. Separating concerns in this way has some advantages: other developers on your team don't need to care how authorization works. Because it stands alone, any optimizations you make to your authorization service help speed up the rest of your overall system.
Of course, this separation of concerns comes at a cost. All authorization data now has to live in one place. Everything that might be used in a decision — a user's membership in an organization, a document's relationship with its organization — must exist inside the centralized service. Either the authorization service becomes the single source of truth for that data, or you have to replicate and sync data from the applications to that central place (more likely). The authorization system has to understand the whole data model that underlies any permission: groups, shares, folders, guests, projects. If those models change often, the system can become a bottleneck for new development. Any change in any microservice might require an update to the authorization service, breaking some of the separation of concerns you might have sought when moving to microservices originally.
There are other factors that make an authorization service tricky: deploying a service that will be responsible for securing every request means that you're responsible for achieving high availability and low latency. If the system goes down, every request is denied. If the system responds slowly to queries, every request is slow.
Google's Zanzibar paper outlines one implementation of this pattern, but it brings along its own challenges. You must insert all your data into Zanzibar as "tuples" (Alice owns this document, this folder contains this other folder, etc). And because it constrains the data it can store, there are certain rules that actually cannot be expressed with Zanzibar alone: rules that have to do with time, request context, or depend on some kind of calculation. Some people call these "attribute-based" rules. An example might be that users are only allowed to create 10 documents per week, or admins can set certain folders to "read only" which prevents edits to their child documents. In these cases, a developer has to write her own policy logic outside of Zanzibar.
The challenge of centralizing your authorization into one place has traditionally prevented most teams from adopting this pattern. Those that do tend to have a lot of services and sufficiently complex data models — it makes sense for them to absorb the added complexity of the authorization service itself. Airbnb, for example, built an authorization service called Himeji to support their model as they moved from a monolith to microservices. It has had a dedicated team of engineers working on it for two years and likely will indefinitely.
But if you could trim away some of this overhead, a centralized authorization service would probably be an appealing option for many teams building with microservices. My team is working on Oso Cloud, an authorization service that combines the benefits of centralized data with the flexibility of leaving some data where it lives. Read about how to use Oso Cloud to build authorization in a microservices backend.
Which microservice authorization pattern should you choose?
When speaking with engineering teams, my guidance is always, "build authorization around the application, not the other way around." For simple systems where maintaining lots of extra infrastructure is expensive, it can be best to keep the data where it lies, and string together your services with purpose-built APIs. Certain applications can grow to massive scale with only basic user roles that can fit on a JWT — in that case, perhaps an authorization gateway is optimal. Some companies with a variety of products, authorization patterns, and user types might prefer to make the effort to centralize their data into a dedicated authorization service.
If you're interested in talking through your authorization system — if you're thinking about making some refactors or if you're just not quite pleased with how it works, get in touch. You can schedule a 1x1 with an Oso engineer, or drop into our slack. We love talking about authorization.
FAQ on Authorization and Authentication in Microservices
What's the difference between authentication and authorization in microservices?
Authentication in microservices is about confirming a user's or service's identity using credentials like passwords or tokens. It's the process of verifying they are who they claim to be. Authorization, on the other hand, determines the actions authenticated users or services can perform within the system, based on predefined roles, policies, or attributes. This distinction is crucial for maintaining system security and data integrity by ensuring only authorized actions are performed.
Why is authorization crucial in a microservices architecture?
Authorization is key in microservices architectures for ensuring that only authorized users or services can execute specific actions, thereby protecting sensitive data and functionalities. It sets access levels and permissions across diverse services, directly affecting security and compliance. Effective authorization mechanisms prevent unauthorized access and activities, essential for the system's integrity and confidentiality.
What are the unique challenges of managing authorization in microservices, and how does a dedicated service help?
Authorization in a microservices environment presents challenges such as ensuring consistent policy enforcement across services, minimizing decision latency, and adapting to changing control requirements. A dedicated authorization service addresses these by centralizing decision-making, providing a unified policy and role source, simplifying management, enhancing performance, and ensuring uniform security across microservices.
What are the main benefits and pitfalls of microservices authentication and authorization?
The benefits include improved security, scalability, and user experience, as services can be independently secured and scaled. The challenges include managing the complexity of securing each service, ensuring consistency across them, and reducing security risks. Addressing these challenges requires a strategic approach that balances flexibility with control.
Considering the importance of authorization, what should companies focus on when building microservices architectures?
Companies should focus on creating a strong, adaptable authorization mechanism that can grow with their microservices architecture. This includes choosing the appropriate model (RBAC, ABAC, or both), using standard communication protocols, and integrating a centralized authorization service to manage complex scenarios efficiently. Such a service simplifies policy management and offers advanced features like policy simulation and real-time updates.
How does leveraging a specialized authorization service benefit microservices security and operation?
Specialized authorization services enhance microservices security and operational efficiency by providing fine-grained control, immediate policy updates, and detailed audit trails. By centralizing complex authorization logic, they alleviate the burden on individual services, ensuring consistent access policy enforcement and streamlining the integration and management of authorization in a distributed environment.
